Upgrading a multi-node vROps cluster can bring significant downtime to the monitoring/data collection abilities of the cluster. The largest production cluster I am responsible for consists of nine data nodes, including the master and master replica, and four remote collectors for our remote data centers. If you recall my previous post Sizing and Installing The vROps Appliance, I discussed the various sizing options of a vROps cluster based on the data collected, and in my case this cluster is configured as LARGE due to the size of our vROps cluster. One of the biggest challenges of maintaining a large cluster, that has remote collectors collecting from data centers in different geographical locations, is the ability to upgrade the cluster with minimal downtime. As it stands now, if I were to upgrade this cluster with the traditional methods VMware provided, I would be looking at a minimal downtime of eight hours. VMware does offer a useful work around: How to reduce update time by pre-copying software update PAK files KB2127895, and we will be using that here.
But first, I wanted to introduce you to a script developed by a Jeremy McCoy, and his repository over at github called nakedhitman. In there you will find this awesome script called vROps Cluster Repair that I have personally used many times, and was recommended to me by VMware’s GSS. This script is intended to bring the vROps cluster back to a known healthy state, and I like to run it before upgrading my Production vROps clusters. You will want to familiarize yourself with that script, download and get it setup with your environment details.
Preparing for the Upgrade
- First – Run the nakedhitman’s – vROps Cluster Repair script. This will cause a brief outage (max 30 minutes) as services are stopped on each vROps node for cleanup. *I recommend taking a snapshot of all vROps nodes beforehand just in case. Once the cluster comes online and starts collecting data, delete those snapshots.
- Second – Insure you have enough free space on the appliances to support the upgrade.
- Third – Complete a basic heath-check of the appliance outlined in my post: vRealize Operations Manager (vROps) Health-Check. While not necessary, I have personally had upgrades fail due to the issues found in this health-check.
- Fourth – Complete Part 1 of VMware KB2127895 article to get the upgrade paks pre-staged on all nodes except the master. No downtime required as this can be done live. The benefit of using this KB us that you are essentially removing the time it takes for the cluster to copy the two pak files around during the upgrade process, which could take hours depending on the size of the environment.
Upgrading The Appliance Cluster
- Snapshot the cluster and remote collectors. Take the cluster offline from the master’s admin page https://<vrops>/admin. The the cluster is offline, shutdown the vrops appliance nodes in order of remote collector, data nodes, master replica and lastly the master. Snapshot the VMs, and then boot the master first, wait for it to fully come up to the appliance login screen, and then boot the master replica, datanodes and remote collectors last.
- Log back into the master appliance Admin page, but do not bring the the cluster online.
- On the left pane select the Software Update tab, and then click the Install a Software Update… button.
- Browse for the PAK file and select it.
- Installation options……
- DO NOT select the option “Install the PAK file even if it is already installed.” – Think of this as a force install. This is used if the original software update failed and you are attempting to try again. This option will ignore the pre-staged PAK files you placed earlier, and severely delay the upgrade as the cluster will now have to copy the PAK files around to each of the nodes.
- You have the option to “Reset out-of-the-box content, overwriting to a newer version provided by this update. Note, user modifications to out-of-the-box alerts, Symptoms, Recommendations and Policies will be overwritten.”
- Click Upload.
- Accept the license agreement.
- Click Next.
- The upgrade will now start. Sit back, and Relax! The upgrade can take hours to complete. There are 9 steps to this.
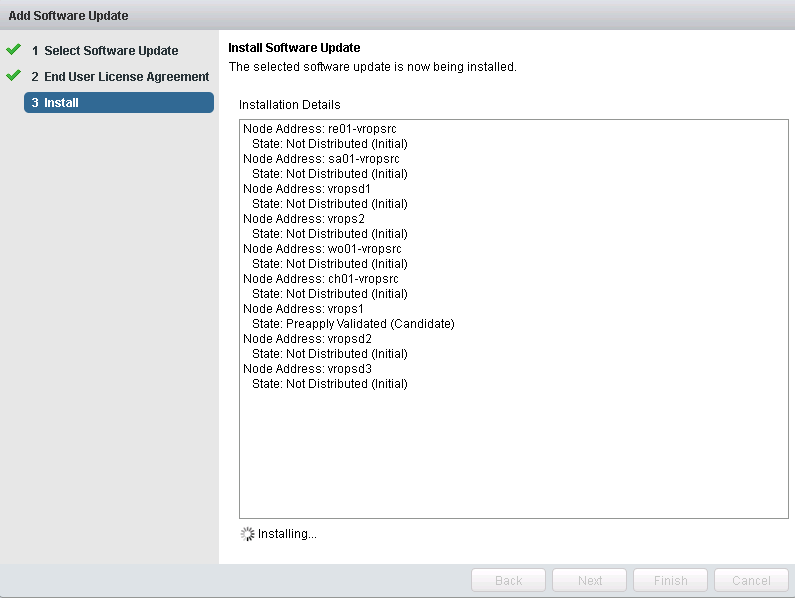
- Eventually you will need to log back into the admin page to monitor the progress of the upgrade. Since 6.2, you can check the status of the upgrade by clicking the little notebook next to each node. If there’s an issue detected like in the screen capture below, it may not stop the upgrade from progressing, but you should take notice. VMware has even started included KB article links to help troubleshoot.
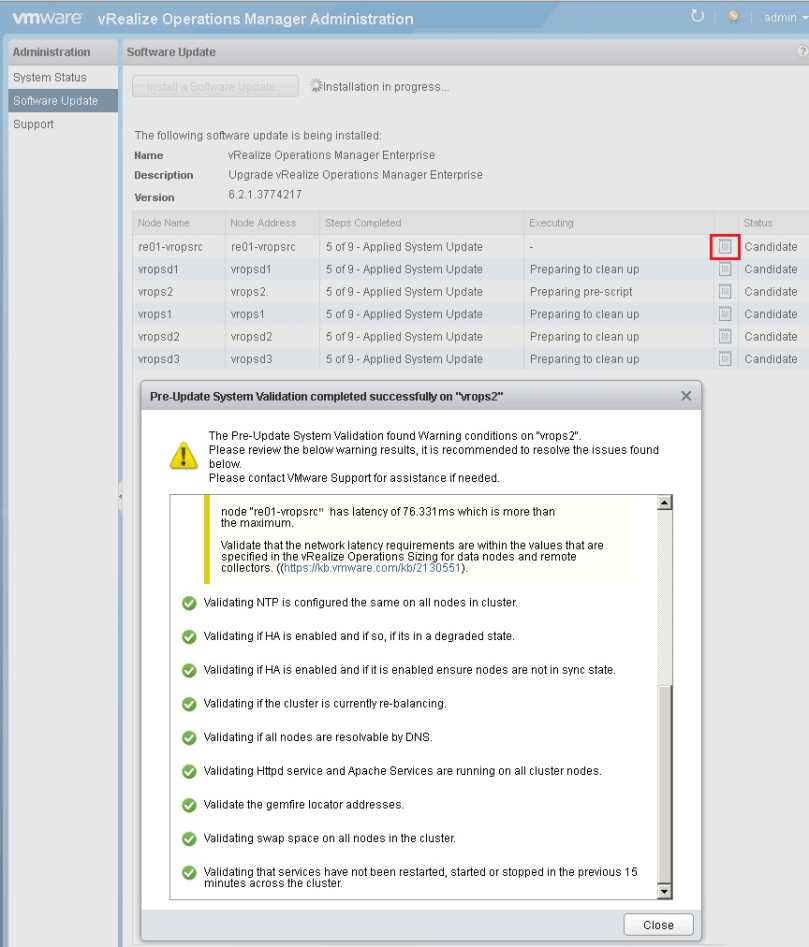
-
There are two places to watch the upgrade on the master at the log level if you’d like:
# tail -f /storage/vcops/log/pakManager/vcopsPakManager.root.apply_system_update.log
–and–
# tail -f /storage/vcops/log/pakManager/vcopsPakManager.root.query.log
- Once the installation is complete and at steps 9 of 9, go back to the system status tab and verify the system state is online with the little green check. VMware engineers have said that at this point the upgrade has completed successfully, and it is safe to remove the snapshots.
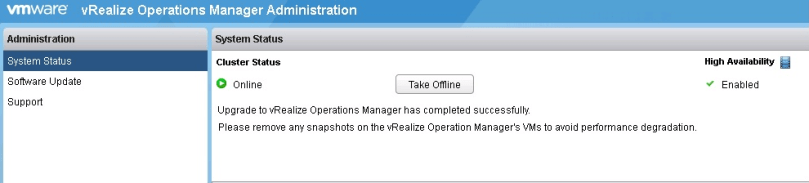
- Should the upgrade fail, open a severity 1 SR with VMware asap.
- If the sun is shining and the upgrade finishes, delete those snapshots, and enjoy all the upgrades/bug fixes the new release brings.
As a side note…
I have submitted a couple feature requests to VMware in order to ease the upgrade process of large vROps installations.
- For multi-data center environments: The ability to have smaller appliances in each data center, with a single search head appliance connected to the multiple data center vROps deployments. The idea here would be a “single pane of glass” to see all data centers like you get if there is a single large muli-node vROps cluster, with multiple remote collectors. Having smaller deployments accessible by a single search head would allow for the ability to take one deployment down per data center at a time to upgrade it, dramatically reducing the data outage, and upgrade time.
- The ability to deploy the latest vROps appliance, and import the data from the old like VMware does with the vCSA. The idea here is that this would be another way to reduce the upgrade time, and reduce the outage occurred by upgrading the appliance.
- Tying #1 and #2 together, the ability to stand up a new appliance in said remote data center, and then export that data centers specific data from the main large cluster to the smaller deployment, or the ability to just stand up a new appliance and import the data from the old one.

You must be logged in to post a comment.