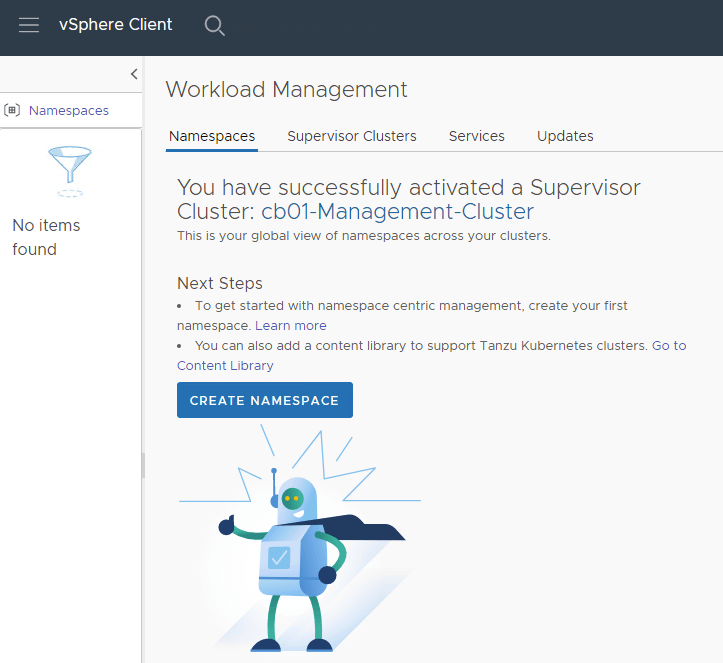
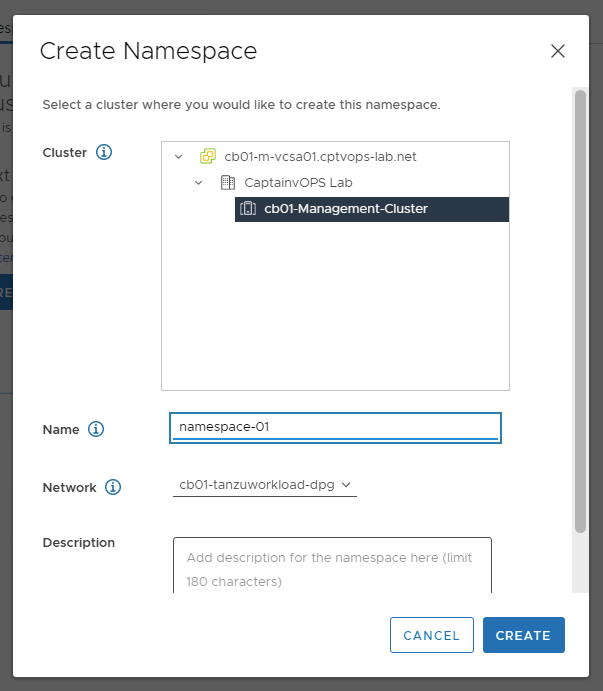
On the workload management screen, you can create your first Namespace on the Namespaces tab by clicking CREATE NAMESPACE.
Be sure to create a Namespace with a DNS compliant name. Click CREATE when ready.
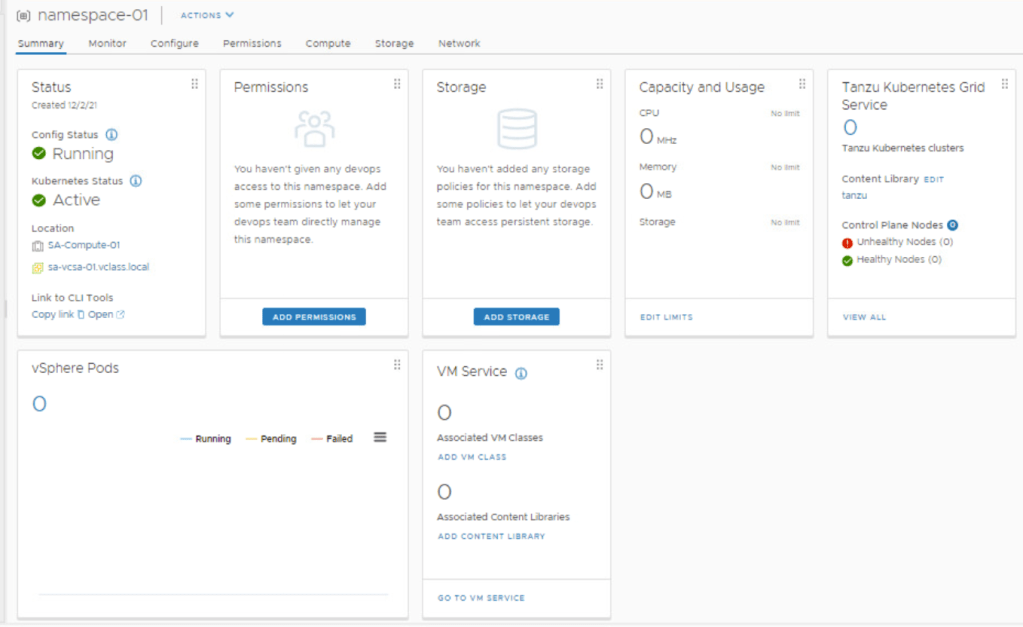
You will also want to set permissions on the Namespace to control access.
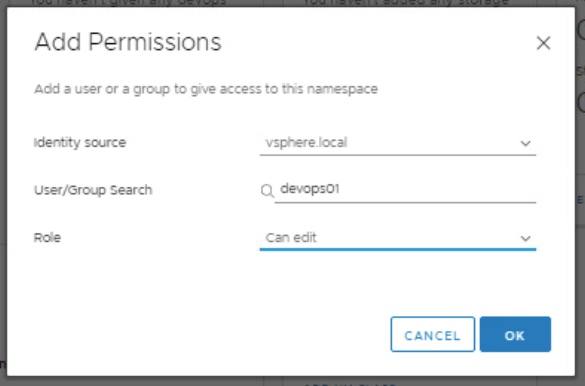
Click Add Permissions
Identity source: <make selection>
User/Group Search: <customer specific>. In this example, I have created a vsphere.local account. You can easily use an active directory account or group here.
Role: <customer specific>. In this example, I have chosen “can edit” that way I can create and destroy things inside the namespace.
Click Ok
(Rinse-wash-repeat as necessary)
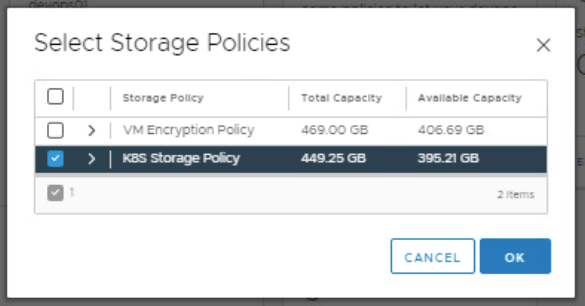
Click Add Storage and add the storage policy.
The namespace is configured with a storage policy and user permissions. The assigned storage policy is translated to a Kubernetes storage class.
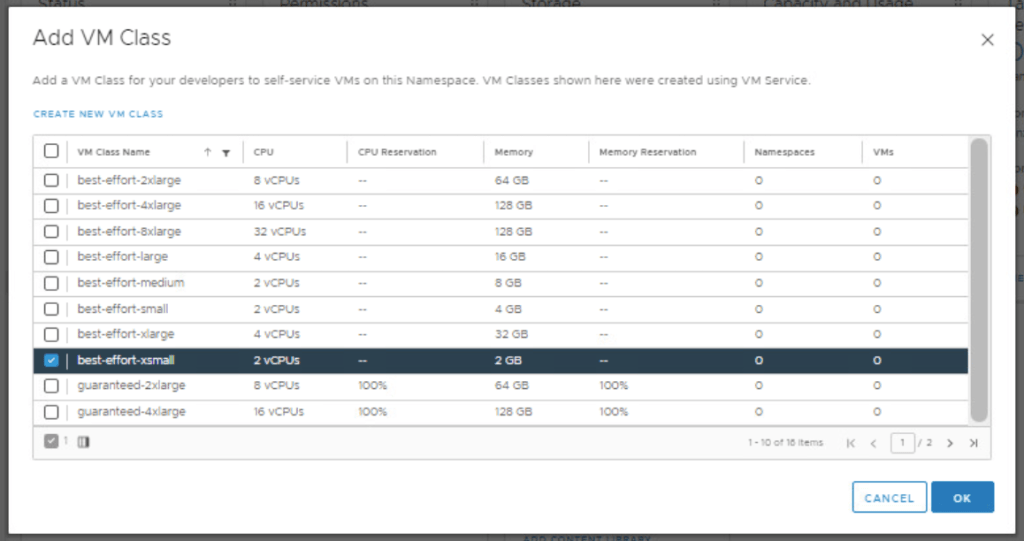
Under VM Service, click Add VM Class. Here we need to associate a VM class with the namespace, that will allow developers to self-service VMs in the namespace. This gives vSphere administrators flexibility with resources available in the cluster. In this example, best-effort-xsmall was chosen because this is a nested lab environment. You should work with your developers to determine the best sizing strategy for the containerized workloads.
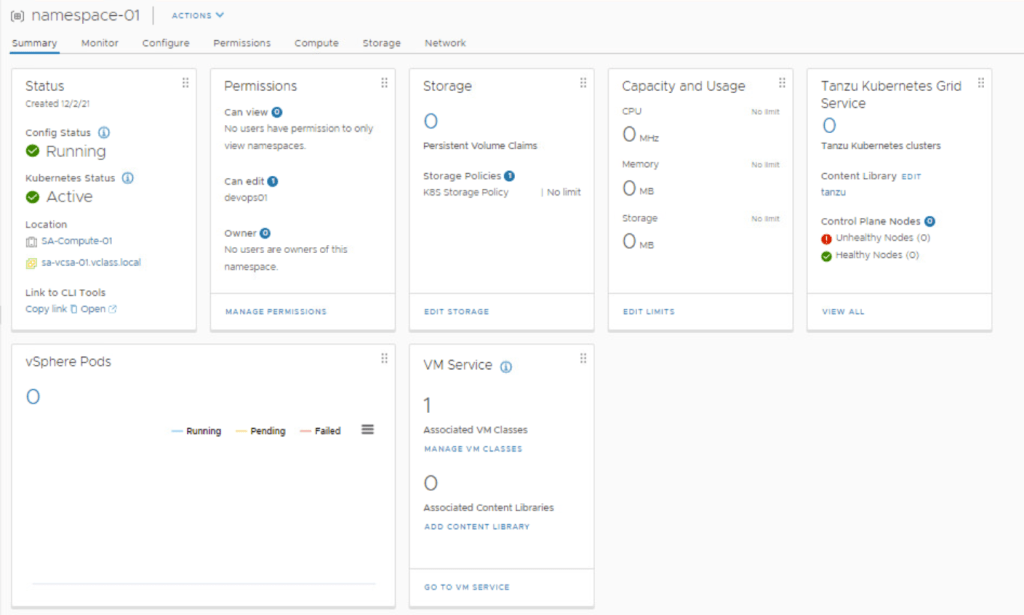
Now that the Namespace, Storage, and VM Class policies have all been defined, your window should look something like:
You are now ready to start deploying Kubernetes workloads to Tanzu.
Blog Date: September 08, 2022 NSX-ALB Controller version: 22.1.1 vSphere version 7.0.3 Build 20150588
In this vSphere with Tanzu NSX-ABL series, I have covered several prerequisites and deployments leading up to this final blog in the series, the actual deployment of Tanzu on the NSX-ALB controller. You can find those blogs here:
If you have been following along in this blog series of Deploying Tanzu with NSX-ALB controller, I have been using a spreadsheet filled out ahead of time for this deployment. We will be referring to it here to it here as well to deploy Tanzu. Note: In this style of deploying the NSX-ALB controller without NSXT networks, we do not get access to the embedded harbor registry.
Prior to deploying Tanzu, you need to create some storage tags and policies (at least one of each), and create a subscribed content library. I go through that setup here.
In this deployment example, I am only using the NSX-ALB controller with no NSX(NSXT) networks. vSphere Distributed Switch is selected by default. Click NEXT in the lower left.
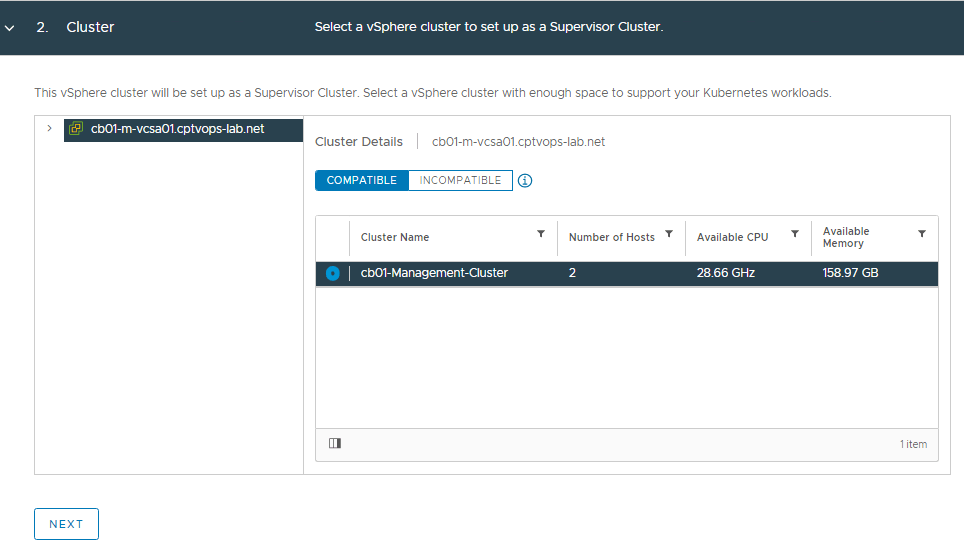
VMware recommends a minimum of 3 hosts in a compute cluster when enabling Tanzu for production deployments. However, this is a lab and I only have 2 hosts available. Select the desired compute cluster with HA and DRS enabled. If no cluster is compatible,
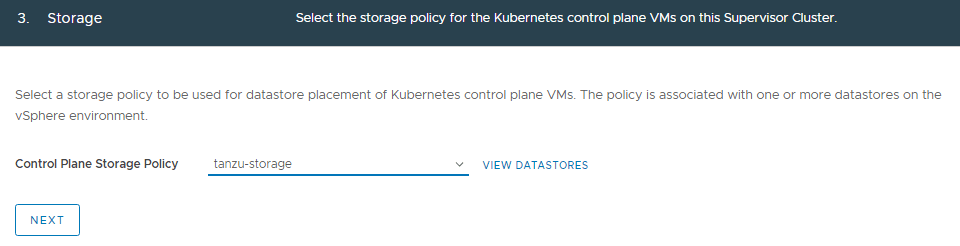
Select the desired storage policy and click NEXT.
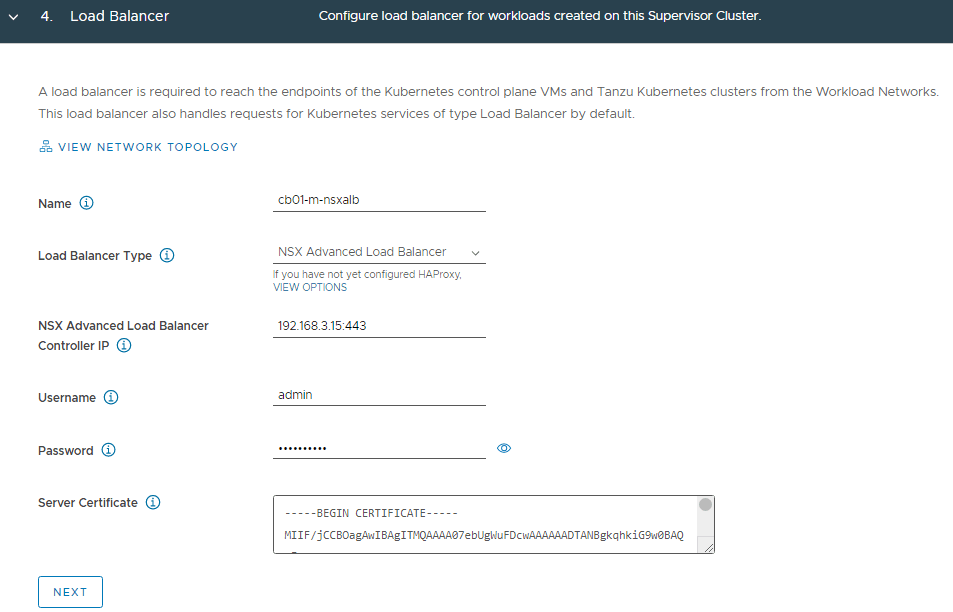
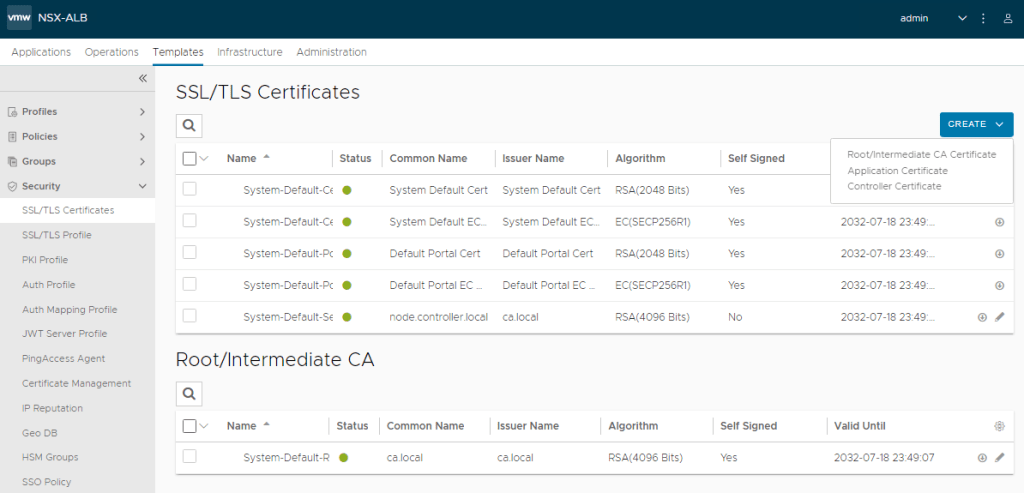
Refer to the spreadsheet, and fill in the information for the NSX-ALB controller. You will also need to log into NSX-ALB and get the certificate for the controller. This can be found on Templates > Security > SSL/TLS Certificates. Click on the down arrow to the right of the controller to export, and then on the new screen that opens, under Certificate, click COPY TO CLIPBOARD.
Click NEXT
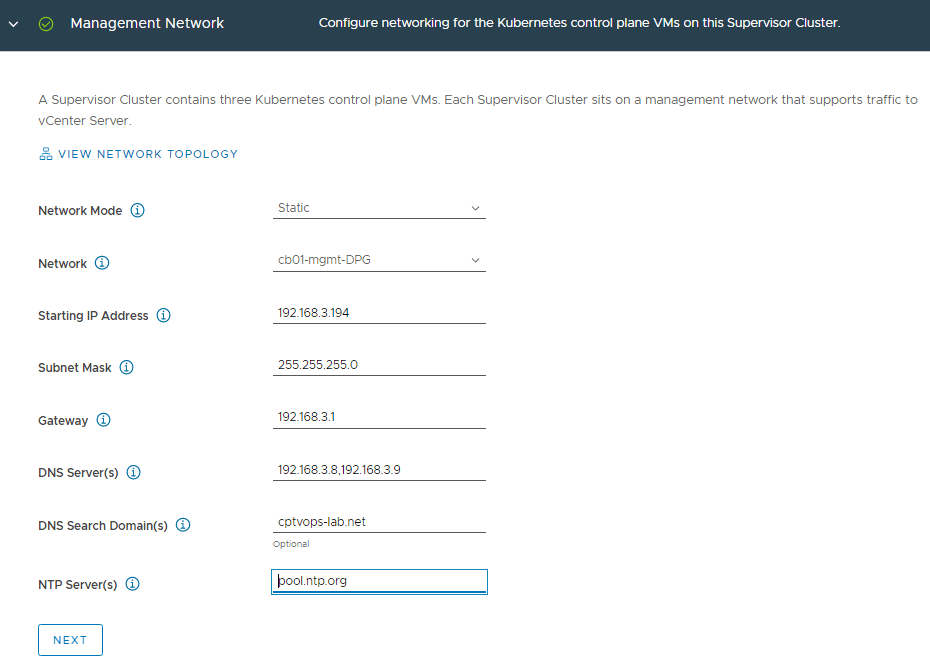
Refer to the spreadsheet, and fill in the details for the management network. Remember the control plane needs a block of 5 consecutive IP addresses.
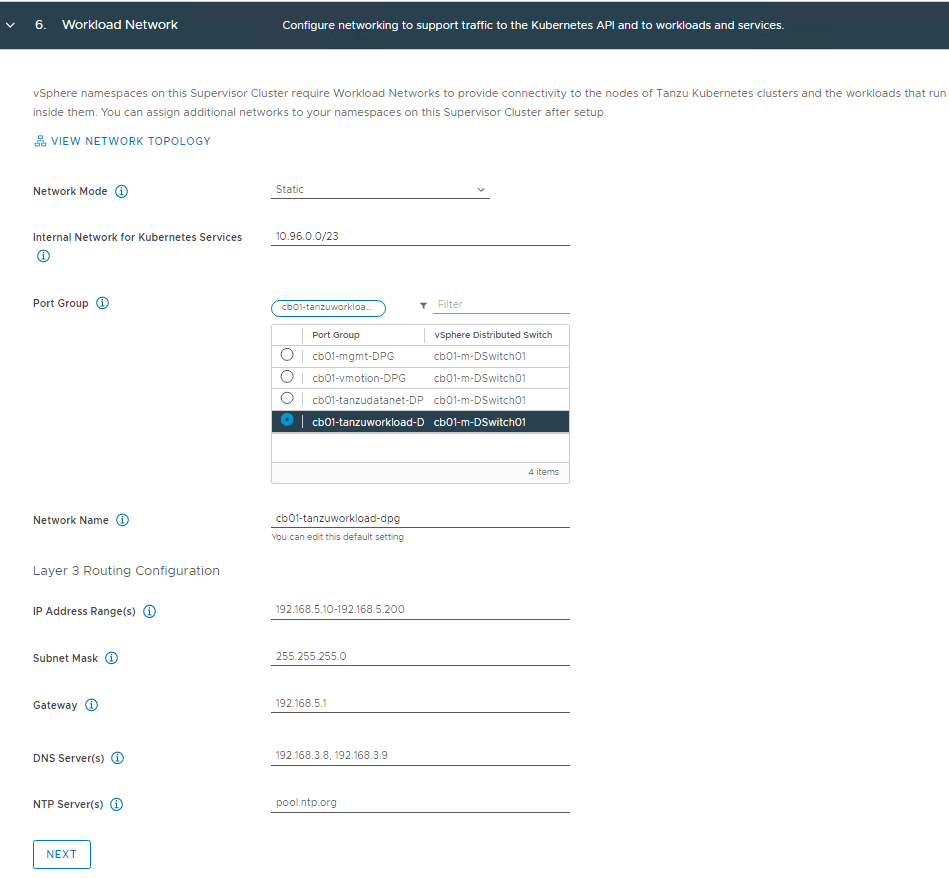
Refer to the spreadsheet, and fill in the details for the workload network. The “Internal Network for Kubernetes Services” default CIDR can be used. You can also specify your own if the default CIDR conflicts with other networks. This is strictly for internal communication.
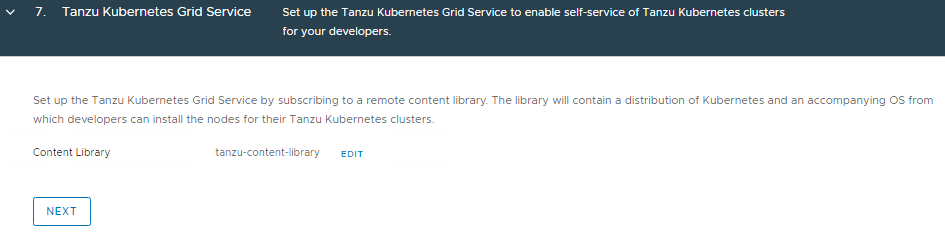
Select the content library we configured earlier.
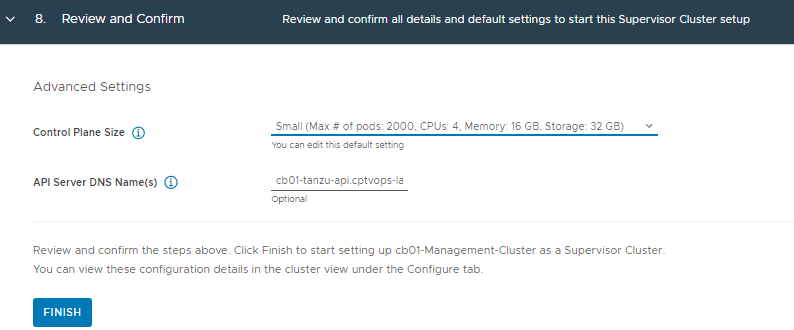
Choose the Control Plane Size that fits your needs and add the API server DNS Name. A word of Caution: Even though the “API Server DNS Name(s)” section says ‘Optional’, I would still fill this in. Currently, there is no easy way to add it after the initial deployment.
Click FINISH
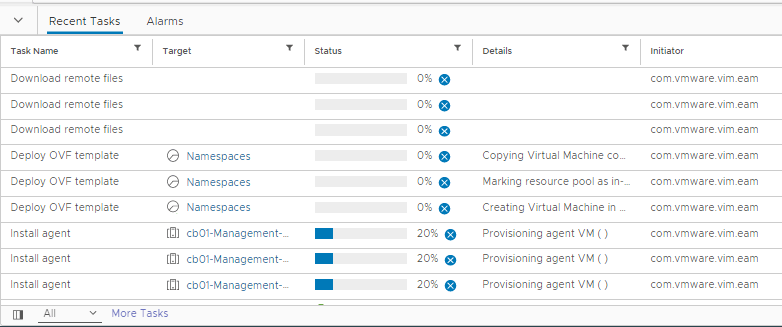
The deployment process can 15 to 20 minutes. Sometimes longer depending on the size of the cluster. Good time to grab a drink…
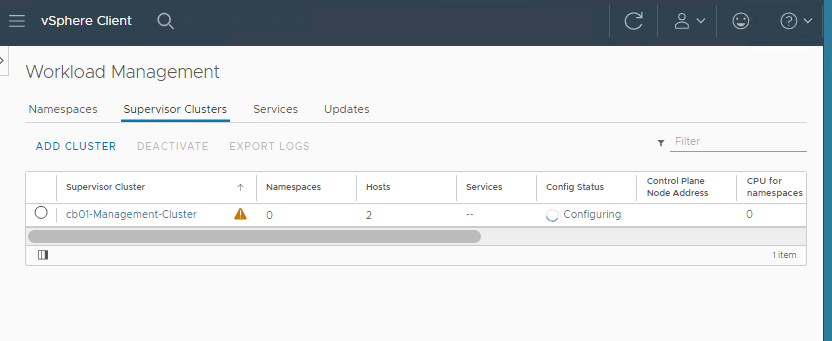
In the vCenter recent tasks window, you should start seeing some deployment activities.
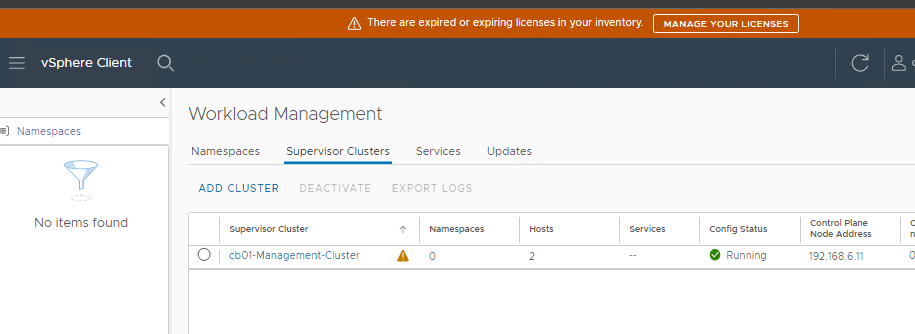
After the deployment completes successfully, there will be a notification bar across the top “TKG plugin has been added”, asking to refresh the browser. After the screen refresh, you should see a config status of Running.
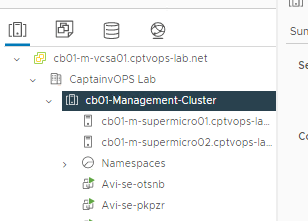
Browsing the vCenter inventory, you should now see a new object called Namespaces, with at least two Avi SE (Service Engine) VMs.
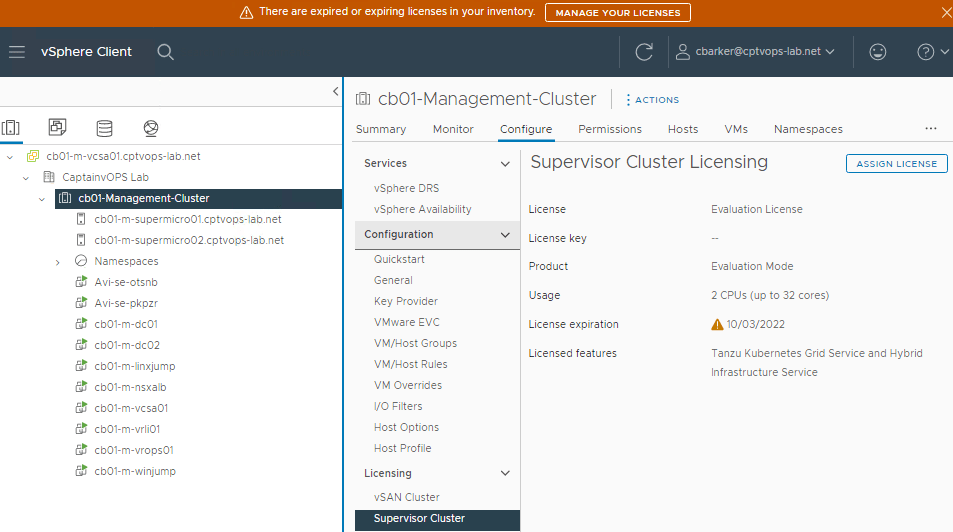
Don’t forget to license the Compute Cluster for Tanzu.
Blog Date: August 16, 2022 vSphere version 7.0.3 Build 20150588
Storage Policies for vSphere with Tanzu
Part of the prep work prior to Tanzu Kubernetes deployment in your environment, is to configure a storage policy or policies for Tanzu workloads. for more information, consult VMware’s Storage Policies for vSphere with Tanzu and vSphere with Tanzu Storage documentation. Here I will walk through the basic configuration we setup for customers to get them started.
Create the Storage Tag
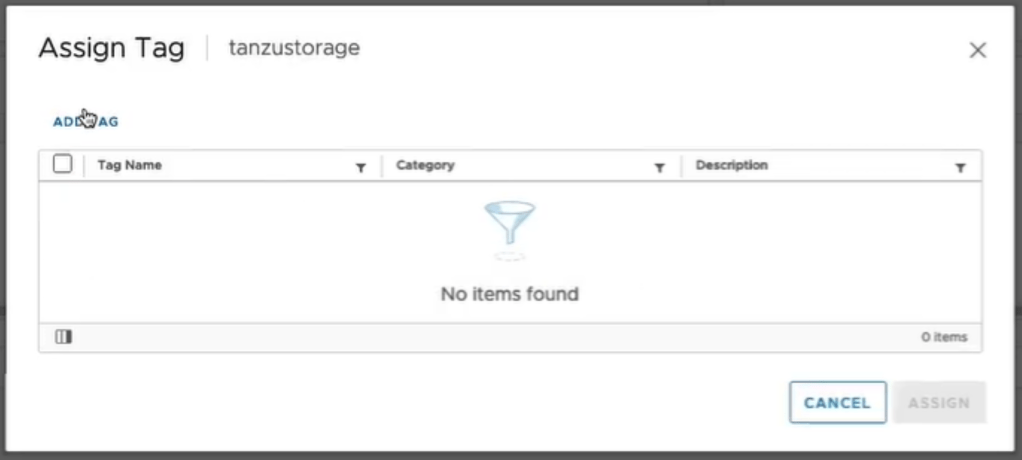
1 – in the vSphere inventory, select the desired storage to house the Tanzu Kubernetes workloads. 2 – Under tags, click assign.
3 – Click Add Tag
4 – Name the tag. In this example we are using tanzu.
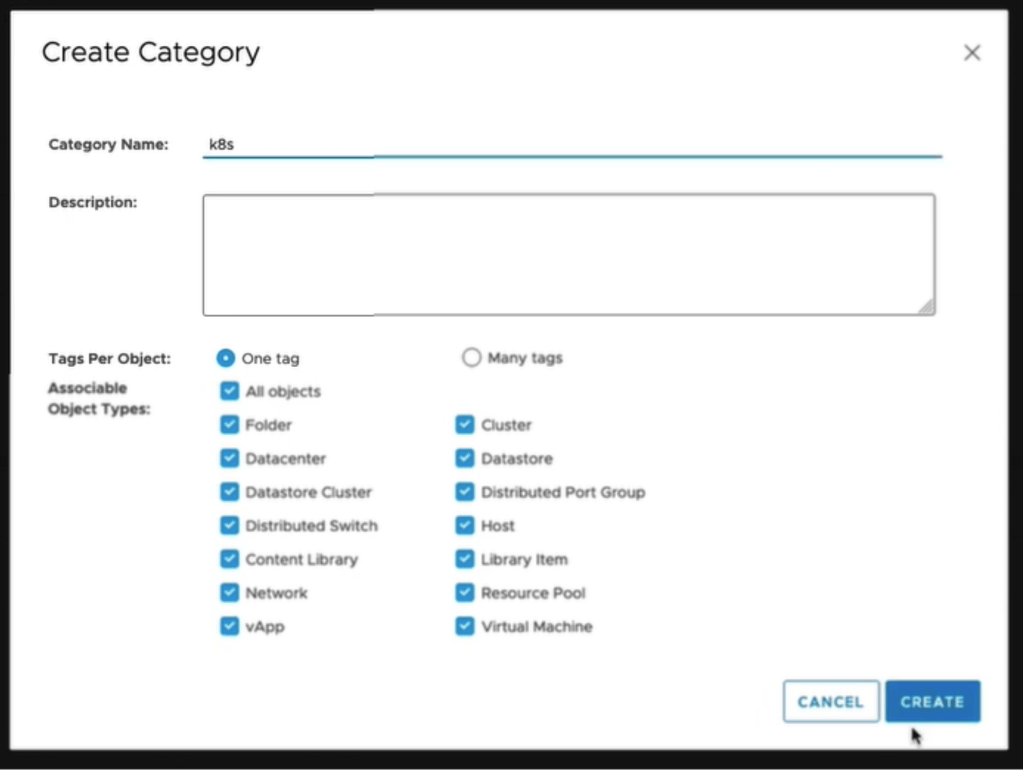
5 – Click the Create New Category, and give it a name. In this example we used: k8s Leave all other defaults, and click CREATE.
6 – Click CREATE again to complete the tag setup.
7 – Assign the newly created tanzu tag to the datastore.
Create and Assign a Storage Policy
1 – On the vSphere menu, select “Policies and Profiles”. 2 – Under VM Storage Policies, click CREATE.
3 – Name the storage profile. Make sure to use a DNS compliant name (lowercase, no spaces). In this example, we used : tanzu-storage. Click NEXT
4 – On Policy structure, Enable tag based placement rules. Click NEXT
5 – On the Tag based placement screen: 5a – Choose the Tag category: k8s 5b – Usage option: Use storage tagged with Tags: tanzu 5c – Click NEXT
6 – On the Storage compatibility screen, the tagged compatible datastores will be listed. Click NEXT
7 – Review and click FINISH.
At this point, we just completed the configuration and assignment of storage tags and policies. Let’s create the subscribed content library for Tanzu.
Create Subscribed Content Library for Tanzu Kubernetes
For more information on creating a subscribed content library for Tanzu Kubernetes, see VMware documentation here.
1 – vSphere Menu, Select Content Libraries, and click CREATE.
2 – Name the new content library (example: tanzu-content-library), select the desired vCenter and click NEXT.
3 – Configure the content library. 3a – Choose “Subscribed content library” 3b – Enter the Subscription URL: https://wp-content.vmware.com/v2/latest/lib.json 3c – Download content frequency depends on customer needs and bandwidth requirement. There’s roughly 27 OVAs available to download.
4 – Click NEXT
5 – Respond yes to the “tanzu – unable to verify authenticity” message. This is expected
6 – Select a security policy if needed, otherwise click NEXT.
7 – Select the storage for the content library.
8 – Review the configuration, and click FINISH
Depending on the chosen sync frequency, you may start to see that a sync has started in the vSphere recent tasks window. If you click on the content library, you can see the available OVAs.
This completes the vSphere environment prep for the Tanzu deployment.
Blog Date: August 12, 2022 NSX-ALB Controller version: 22.1.1 vSphere version 7.0.3 Build 20150588
In my previous blog: vSphere with Tanzu: Deployment of NSX-ALB Controller, I went over the basic NSX-ALB controller deployment and activation. In this blog, I will go over the configuration of the controller in preparation of deploying Tanzu to the target workload compute cluster.
Picking up where I left off previously, I just assigned the Essentials license to the controller.
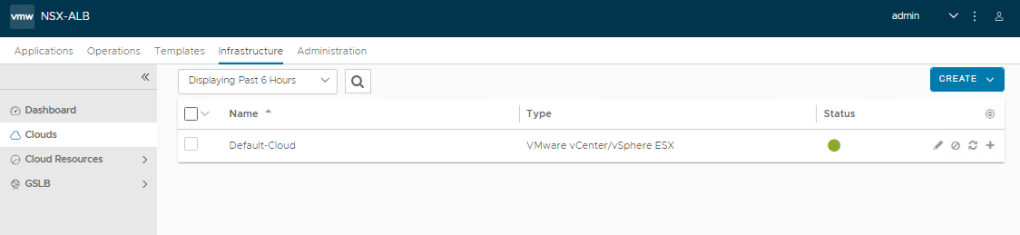
Next, we need to configure our default cloud.
Configure the Default Cloud
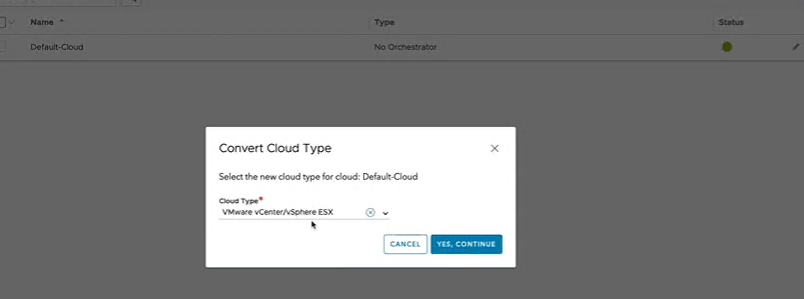
Click on the Infrastructure tab, then select Clouds in the left menu. We see the controller comes with a default cloud already configured, and we can edit this for our needs. To the right of the green dot, you’ll see several icons. Click the gear to the right of the pencil.
On the Convert Cloud Type window, select “VMware vCenter/vSphere ESX” in the cloud type drop menu. Click YES, CONTINUE.
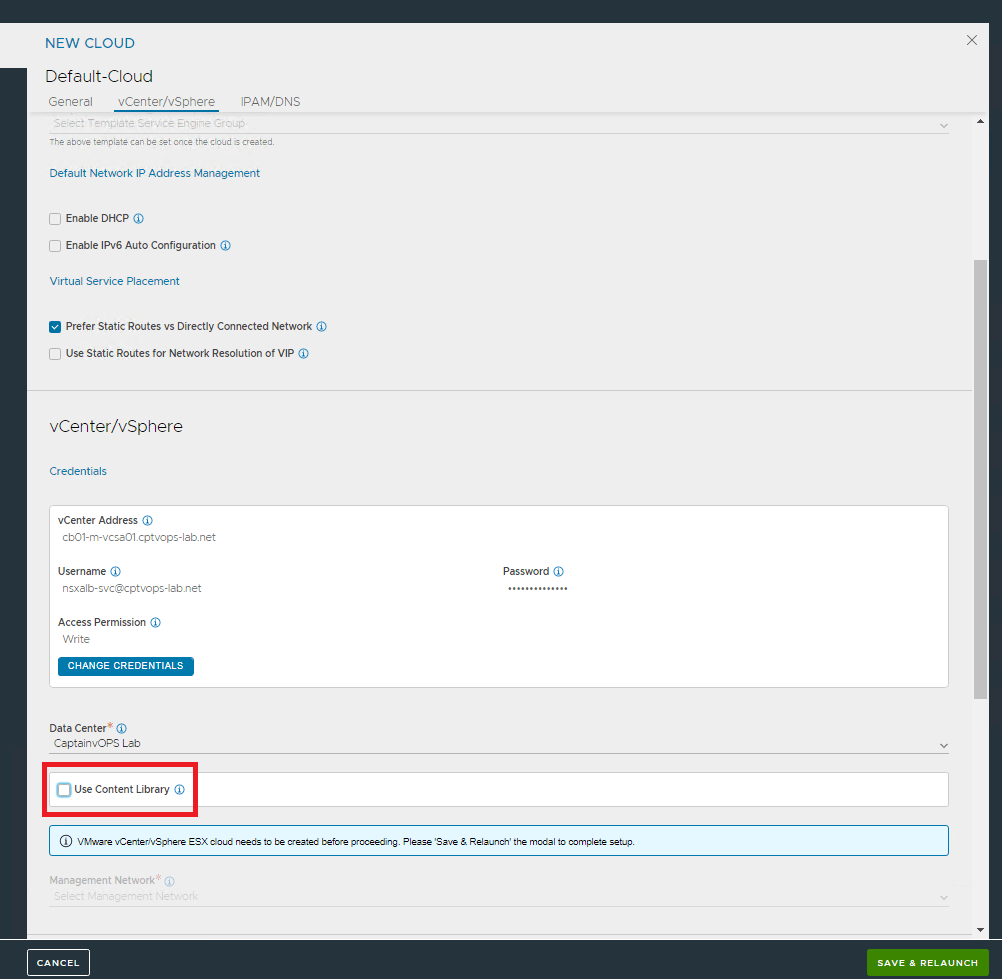
For the Default-Cloud, select “Prefer Static Routes vs Directly Connected Network” under Default Network IP Address Management.
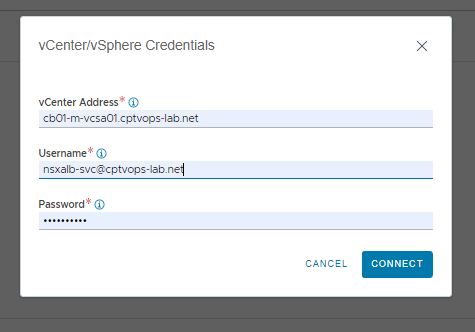
Then under vCenter/vSphere section, click add credentials.
Here you will need to add the FQDN of the vCenter, along with the service account the controller will use to access the vCenter. We can use the example spreadsheet we filled out earlier. Click CONNECT.
This will kick you back to the setup wizard. However we now see a little blue information bar “VMware vCenter/vSphere ESX cloud needs to be created before proceeding. Please ‘Save & Relaunch’ the modal to complete setup.” However, the SAVE & RELAUNCH button in the lower right corner is grayed out. We first need to deselect the “Use Content Library” . Now we can click save & relaunch.
Make sure Data Center drop menu has the desired data center, else select it.
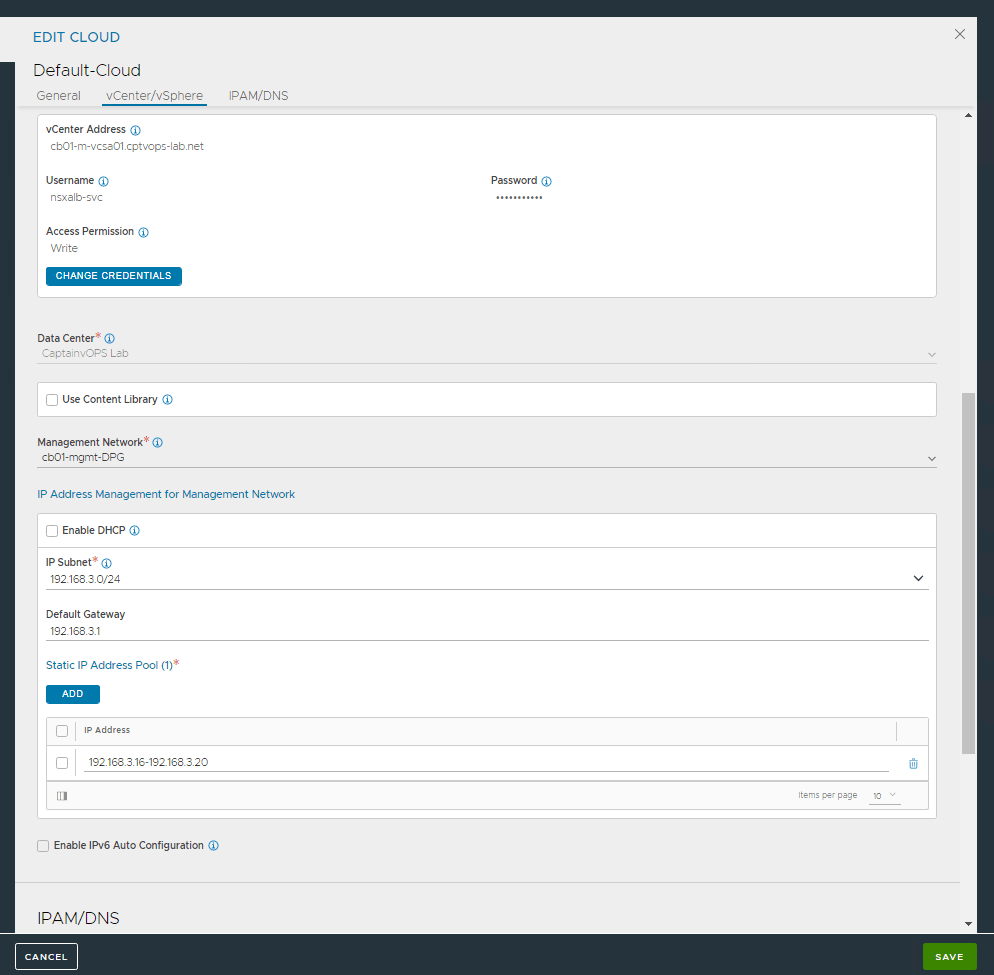
Now we can configure the management network information. Select the management network, add its CIDR and gateway. Under the Static IP Address Pool, we need to click the ADD button. This will need 5 consecutive IP addresses.
Click the SAVE button in the lower left. We will come back and edit this section later on.
Configure the NSX-ALB Controller to use a certificate
Now we need to update the NSX-ALB SSL certificate. We can either use a self signed certificate, or we can create a CSR and sign the certificate with a CA. In my lab, I have applied the signed CA certificate.
Check out my blog where I go over both options and how to create them here: vSphere with Tanzu: Replacing NSX-ALB Controller CertificatesApplying a certificate to the controller has to be done before proceeding to the next step! ________________________________________________________________________________
Configure the Service Engines
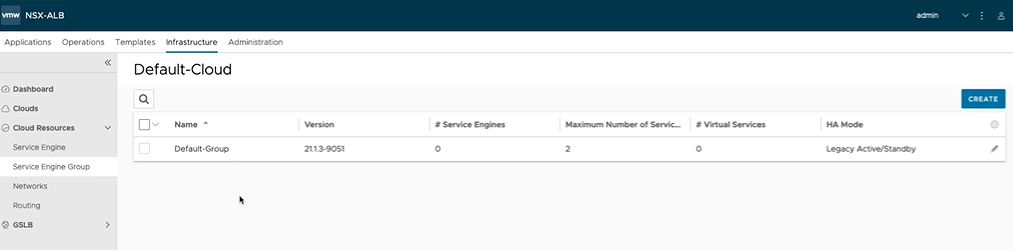
For that, we click the Infrastructure tab, and then on the left we expand Cloud Resources, and select Service Engine Group.
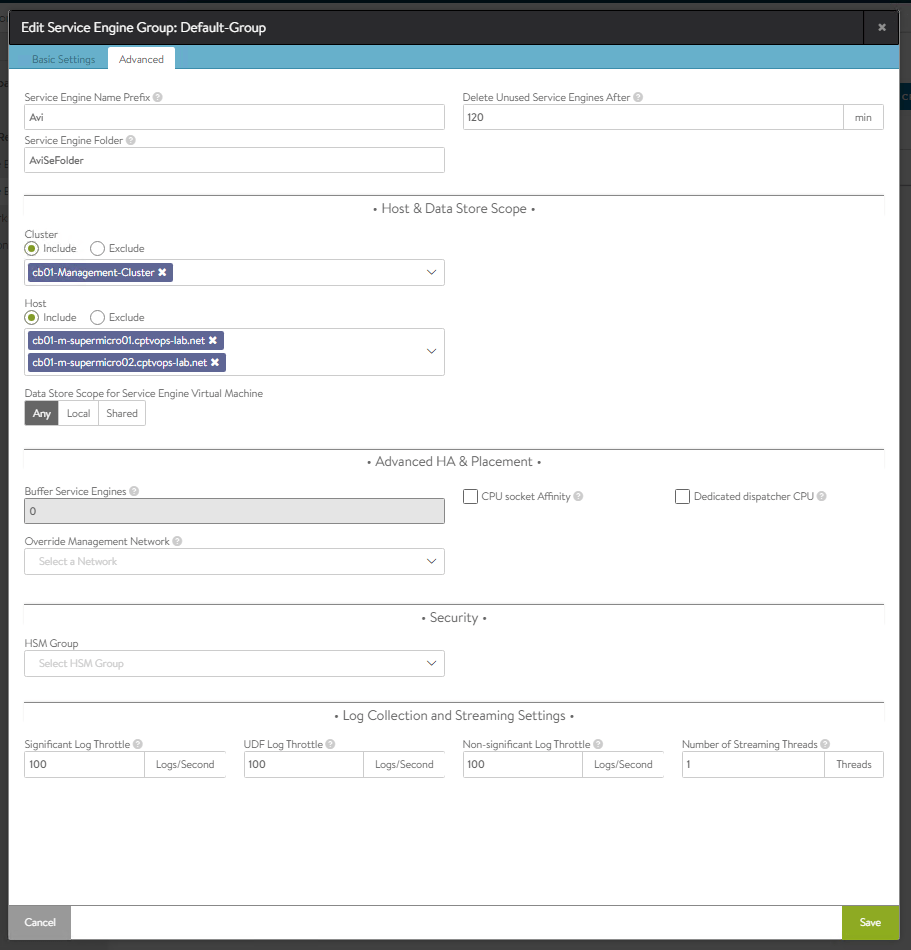
1 – Click the pencil on the default-group. 2 – The default configuration, the Legacy HA is already configured to be Active/Standby. This is the only mode available to the essentials license. 3 – The number of Virtual Services per Service Engine, is 10 at default. This is the number of load balancing services the SE will support. Each Tanzu cluster you create, will consume one of these load balancing services, and every service you expose from the tanzu cluster will consume a service. This can be turned up to 1000 depending on your needs. 4 – The maximum number of service engines is limited by the essentials license used.
Click on the Advanced tab.
Under cluster we need to select the workload cluster that will run Tanzu, and we need to specify all hosts.
Click Save in the lower right.
Configure The NSX-ALB Controller Networks
Now that we have configured the Service Engine in the previous section, we now need to configure our networks. On the left menu, select Networks under Cloud Resources. We can see that it has detected all of our available networks in the vCenter.
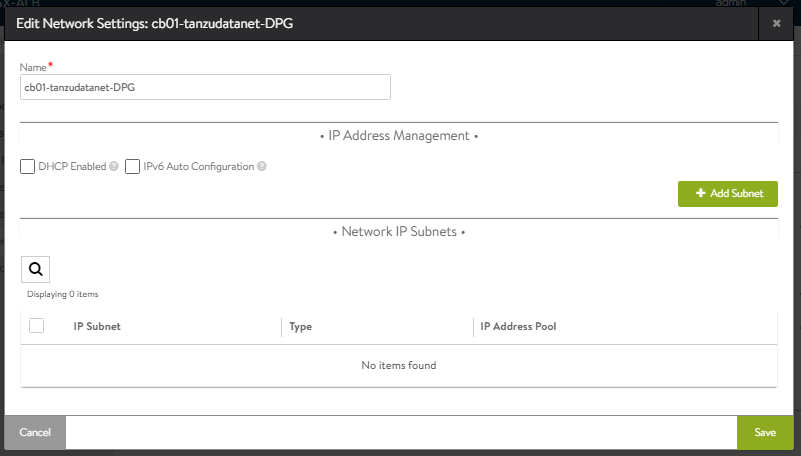
You’ll notice that it does not detect the network settings because we are using static IPs instead of DHCP, so first we will edit the Data network. Click the pencil on the right.
Click the ‘+ Add Subnet’ button. Refer to the spreadsheet again, copy the ‘Data Network CIDR address’, and paste it into the ‘IP subnet field’. Also click the ‘+ Add Static IP Address Pool’ button, and copy the pool for the Data Network off the spreadsheet. End result should look similar to this.
Click Save in the lower right. Click SAVE again on the next screen. Now the Data network is configured. Next we need to configure the routing.
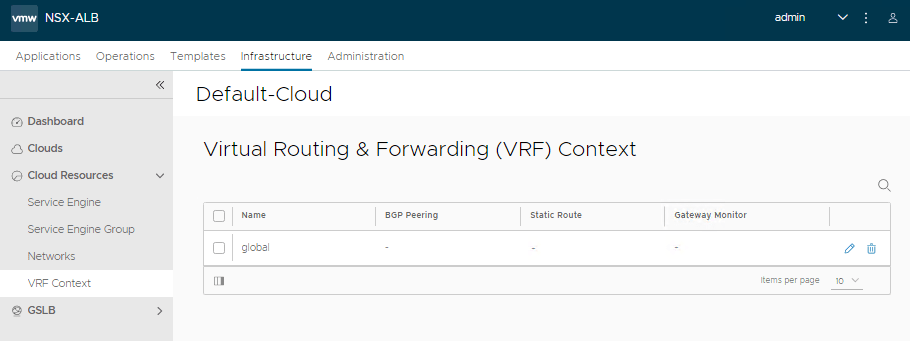
On the left hand side, select VRF Context to configure the routing. To the right of ‘global’ select the edit button.
We need add the default gateway route and set to 0.0.0.0/0. In the Next hop, we can add the gateway for the data network from the spreadsheet.
Click Save in the lower right.
Now the Data network has been setup.
Configure the IPAM profile
Next, we need to make sure that the NSX ALB knows which IPs it should use, so we need to setup an IPAM as well.
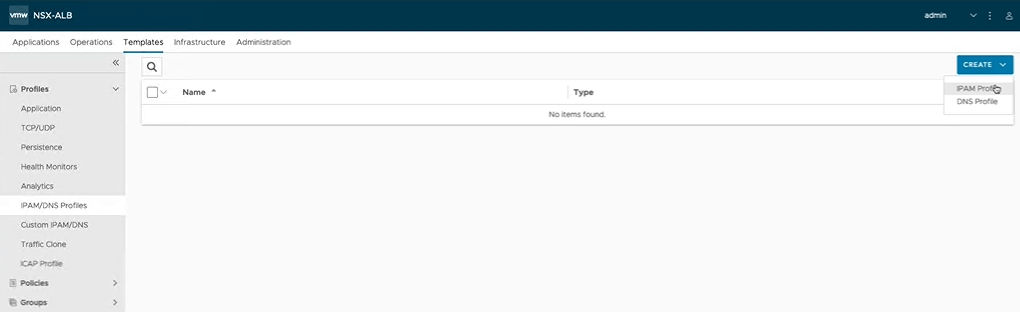
1 – Click on the Templates tab, and then under Profiles, select IPAM/DNS Profiles. 2 – Click the CREATE button, and select ‘IPAM Profile’ from the drop menu. With the essentials license, we can only create an IPAM Profile.
1 – Name the profile. In this example we use: tanzu-ip. 2 – Under Cloud, select Default-Cloud in the drop menu. 3 – Under Usable Networks, click the ADD button, and in the lower menu, select the data network.
Click SAVE in the lower right.
Now the IPAM profile is configured.
Assign the IPAM profile to the Default-Cloud
Next we need to assign the IPAM to the default cloud. Click the Infrastructure tab, select Clouds, and then to the right of the default-cloud, click the edit button.
Now we can update the default-cloud IPAM Profile, with the IPAM profile just created.
Click SAVE in the lower right. Next, wait for the status to turn green if it hasn’t already.
Congrats! We have finished the setup for the NSX-ALB Controller, and are now ready to deploy Tanzu. I’ll cover that in my next blog. Stay tuned.
Blog Date: August 12, 2022 NSX-ALB Controller version: 22.1.1 vSphere version 7.0.3 Build 20150588
In this post, I’ll be going over the steps to replace the SSL/TLS controller certificate. You can either replace the controller certificate with one from a Certificate Authority, or you can create a self signed certificate that includes the FQDN and IP in the SAN. This information is missing in the default certificate, and it will cause the deployment of Tanzu to barf if not done. In this blog I will cover both methods.
(OPTION A) Replacing the NSX-ALB Controller SSL/TLS Certificate using a CA.
The following process is what I used in my lab to replace the NSX-ALB controller certificate using my Microsoft CA. Your mileage may vary.
Remember to take a snapshot of the NSX-ALB controller before proceeding.
1- First we will need to generate a CSR. In the NSX-ALB interface, go to: Templates -> Security -> SSL/TLS Certificates. 2 – Click the blue “Create” button in the upper right, and select Controller Certificate from the drop-down menu.
Enter the name of the certificate, and then under Type, select CSR.
Add the certificate information, and then add the FQDN and IP address to the subject Alternate Name (SAN). I am doing this example in my home lab, so I only have a single controller. Large deployments might have clustered controllers, so your configuration will very if you have multiple SANs to add.
Click the green “Save” button in the lower left.
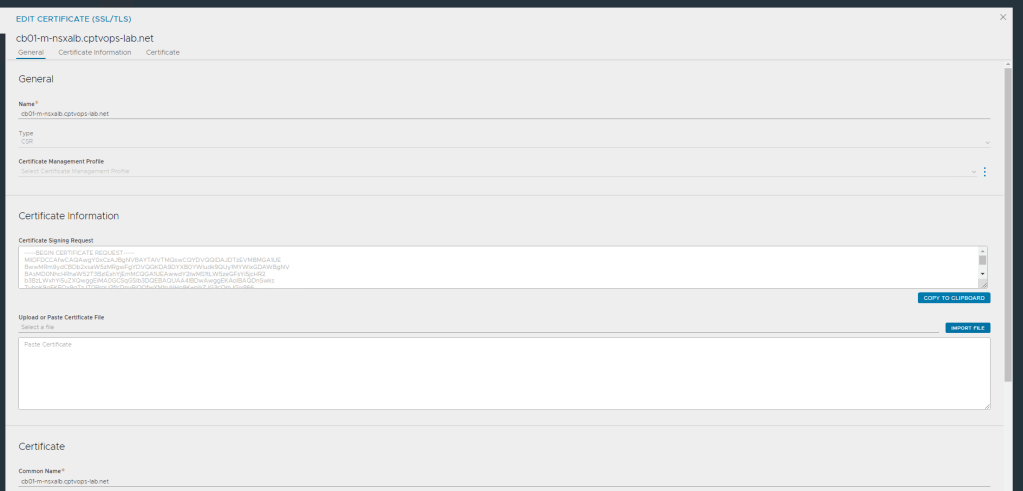
Now you will see the certificate in a grey status in the list. Click the pencil icon on its right side to edit it.
Now we need to copy the Certificate signing request to take over to our CA. Click the “Copy to Clipboard” button.
Now we need to connect to the Microsoft CA web portal. Click “Request a Certificate”.
Click on “advanced certificate request”.Past the certificate request into the box. *Caution* -> Make sure there is no empty line after —–END CERTIFICATE REQUEST—–.
For this certificate, you will need to use the “Web Server” template on the Microsoft CA. I have created a VMware version of it following VMware’s KB article 2112009 for Creating a Microsoft Certificate Authority Template for SSL certificate creation in vSphere 6.x/7.x. I called my web server template VMware, so that is what I have selected here.
Click “Submit”.
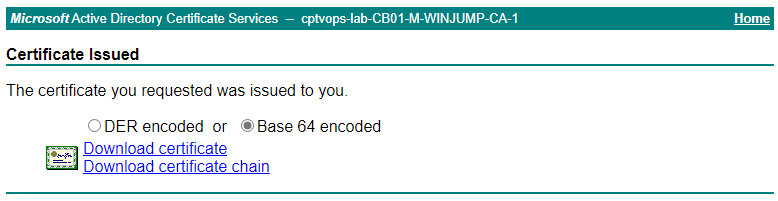
Select “Base 64 encoded”, and then click the “Download certificate” link.
We also need to obtain a copy of the root ca certificate from the Microsoft CA to complete the chain.
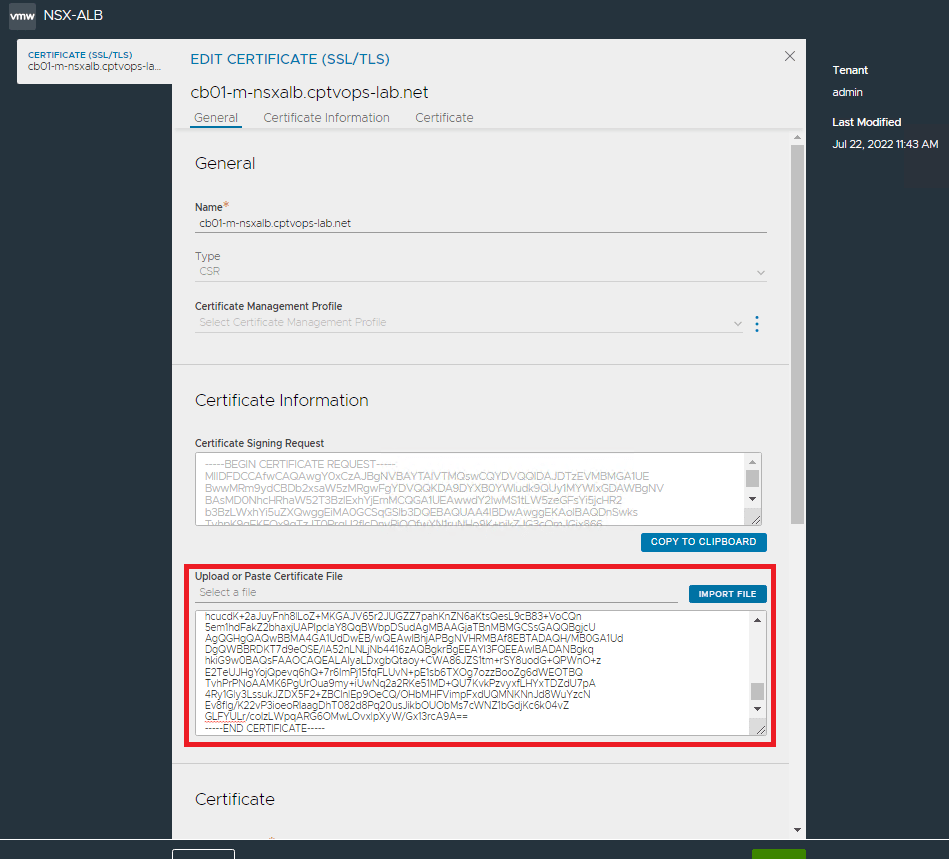
In order to complete the cert chain, in a text editor like Notepad++, paste the NSX-ALB SSL certificate you created first, and then paste the root ca certificate from the Microsoft CA. It should look like this:
Now you have the full chain, so copy it. Go back to the pending controller certificate in the NSX-ALB interface, and paste the full chain into the window.
Click the “Save” button in the lower left corner.
Now back to the main SSL/TLS Certificates window, we should see that the controller SSL certificate has a green status. You might need to refresh the page a couple of times. If the controller SSL certificate is invalid, a little exclamation symbol will appear next to the certificate, and you will need to troubleshoot further.
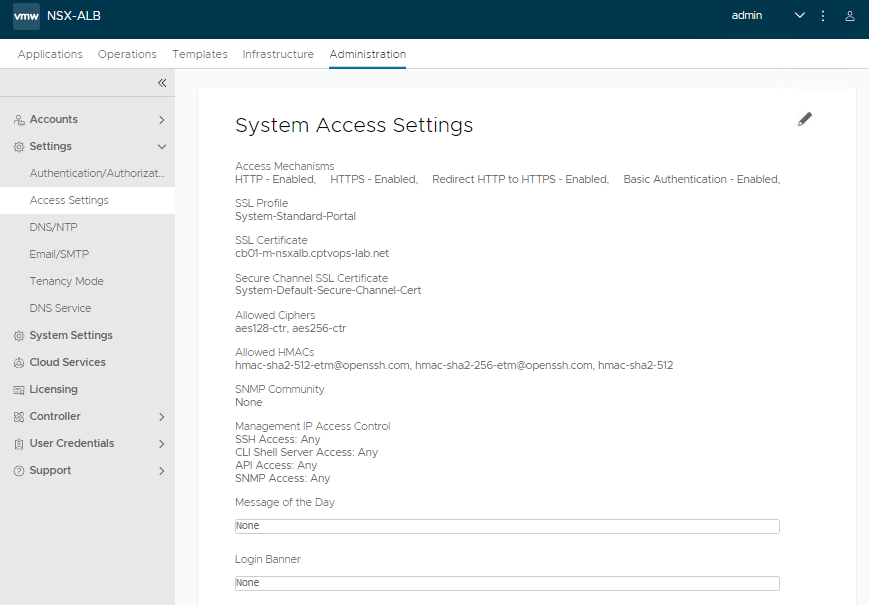
Assuming the SSL certificate is proper, we now need to apply it to the NSX-ALB controller. Go to Administration tab, In the left menu expand Settings, and then select Access Settings.
Click the pencil in the upper right, to edit the system access settings.
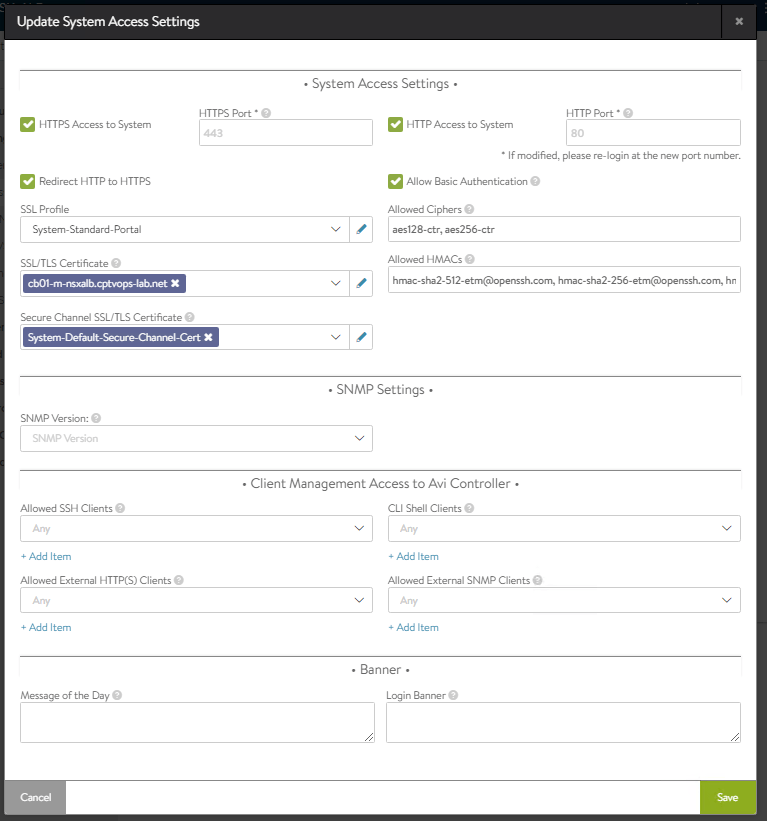
On the Wizard that opens, on the left hand side you’ll see ‘SSL/TLS Certificate’ and it will have the default certificates in it. Click the ‘X’ on those to remove them.
Select the new NSX-ALB controller certificate you imported. Click the ‘Allow Basic Authentication’ check box as well and add the check mark.
Click the “Save” button in the lower right. After 5 to 10 seconds, the certificate will be updated on the controller. Close and reopen your browser to see the newly installed certificate.
That’s it for replacing the NSX-ALB controller certificate. Not terrible once you understand the process. Don’t forget to clean your room, and delete the snapshot you took prior.
(OPTION B) Replacing the NSX-ALB Controller SSL/TLS Certificate using self signed method.
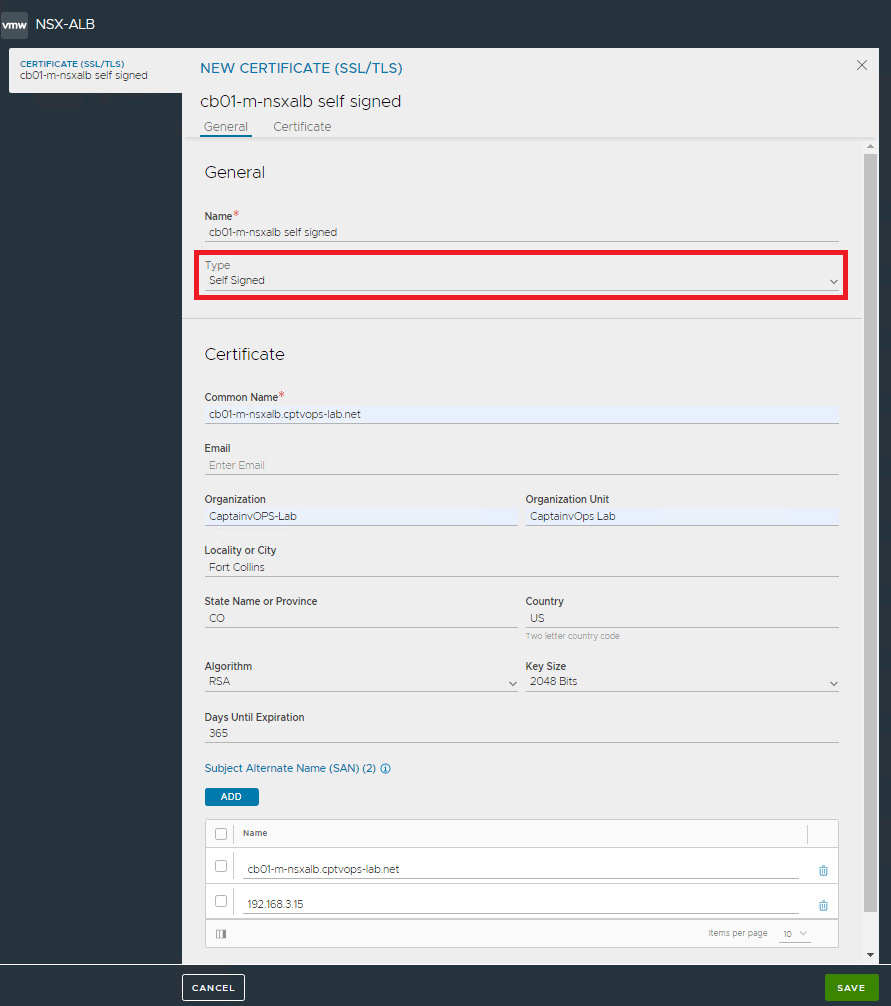
1 – In the NSX-ALB interface, go to: Templates -> Security -> SSL/TLS Certificates. 2 – Click the blue “Create” button in the upper right, and select Controller Certificate from the drop-down menu.
Type: Self Signed will be selected by default. Add the certificate information, and then add the FQDN and IP address to the subject Alternate Name (SAN). I am doing this example in my home lab, so I only have a single controller. Large deployments might have clustered controllers, so your configuration will very if you have multiple SANs to add. Fill in the details below to complete the self signed certificate. Click Save.
We now need to apply it to the NSX-ALB controller. Go to Administration tab, In the left menu expand Settings, and then select Access Settings.
Click the pencil in the upper right, to edit the system access settings.
On the Wizard that opens, on the left hand side you’ll see ‘SSL/TLS Certificate’ and it will have the default certificates in it. Click the ‘X’ on those to remove them.
Select the new NSX-ALB controller self-signed certificate in the SSL/TLS Certificate drop menu. Click the ‘Allow Basic Authentication’ check box as well and add the check mark.
Click the “Save” button in the lower right. After 5 to 10 seconds, the certificate will be updated on the controller. Refresh the page a couple of times, and you might get the “Potential Security Risk Ahead” warning message in the browser. Else you might need to close and reopen your browser to see the newly installed certificate.
That’s it. Using a self-signed certificate is a straight forward process. Most production deployments will use a CA signed certificate. Don’t forget to clean your room, and delete the snapshot you took prior.
In my next blog: vSphere with Tanzu: Configuring the NSX-ALB Controller, I continue on and configure the NSX-ALB controller to use with Tanzu.
Blog Date: August 11, 2022 NSX-ALB Controller version: 22.1.1 vSphere version 7.0.3 Build 20150588
In my previous blog: vSphere with Tanzu: NSX-ALB Controller Requirements and Deployment Prep. I went over the basic requirements and prep work for the NSX-ALB controller to use with Tanzu. In this blog, I’ll demonstrate deploying the NSX-ALB into my home lab. In this blog, I will be doing the basic NSX-ALB controller in my lab with no NSX-T.
NOTE: Production deployments should use NSX-ALB controller cluster. In my lab however, I am only deploying a single controller for this example.
NSX-ALB Controller Deployment
Obtain the NSX-ALB controller by following the VMware KB Article 82049. In this example I am using version 22.1.1
Import the Controller OVA into the vCenter.
OVA Import Step 3: The controller would need to be deployed on a Compute Cluster that has access to the networks configured for this deployment. Click NEXT.
OVA Import Step 5: Select storage that the desired Compute Cluster has access to.
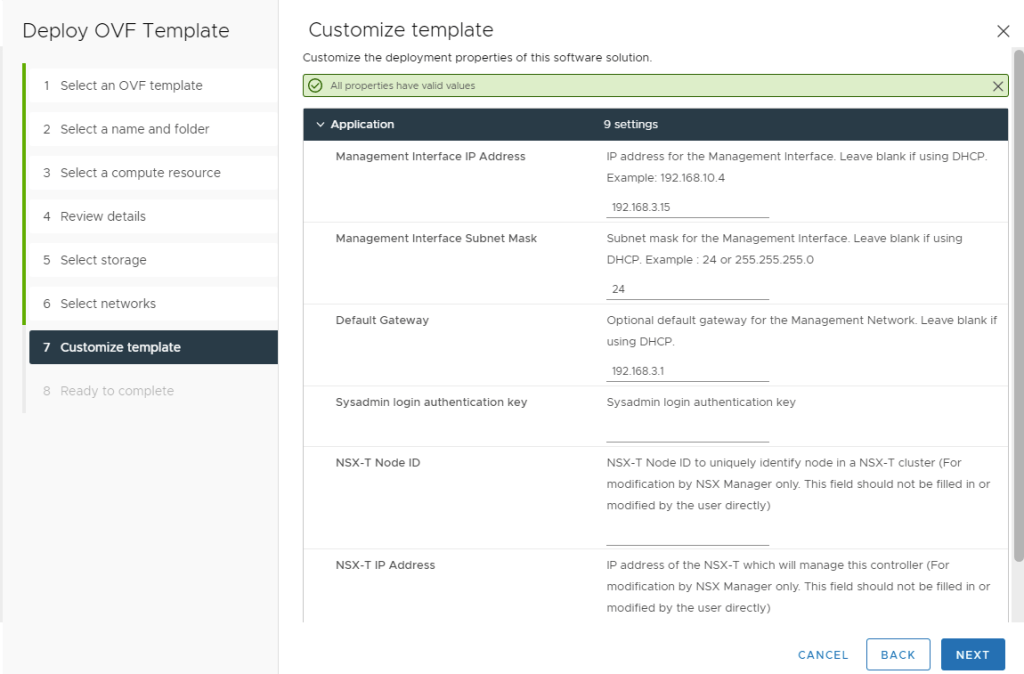
OVA Import Step 6: Select the management network distributed port group in the excel we filled in earlier, and click NEXT.
OVA Import Step 7: fill out the networking information for the NSX-ALB controller. Here we just need to add the controller IP, subnet, and gateway. Click NEXT.
OVA Import Step 8: Check for accuracy, and then click FINISH to start the deployment.
Once the NSX ALB OVA is deployed, start the VM. Wait for the VM to fully boot, and then access the web interface.
On the first login, you will need to create the admin password. Click CREATE ACCOUNT
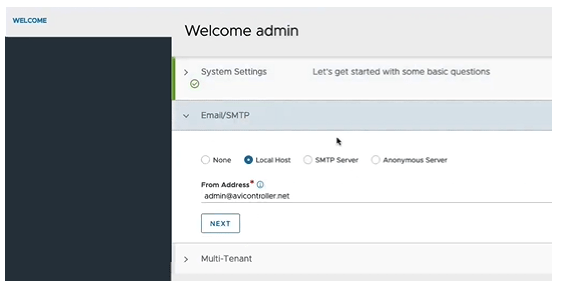
After the admin account is created, you’ll need to add the DNS resolver(s) and DNS Search Domain. Click NEXT.
Add the “from” email address of your choosing. For this example, I am just using Local Host. Click NEXT.
For the multi-Tenancy, the defaults can be used unless otherwise specified. Toggle the check mark in the “Setup Cloud After” in the lower right because we want to configure the cloud component later, and click SAVE.
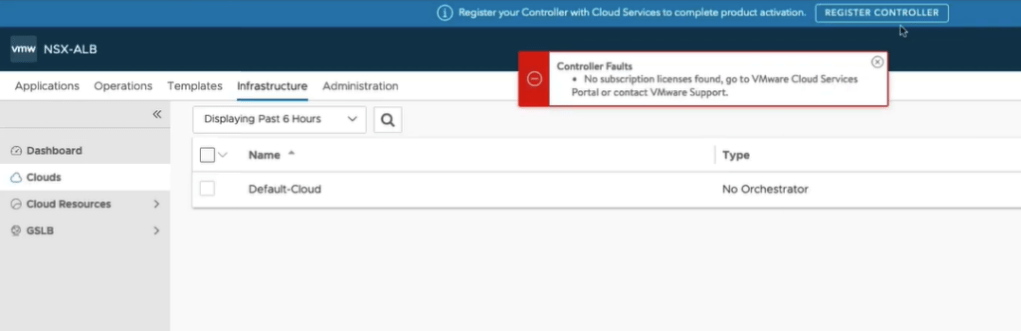
Now we are logged into the admin interface, and are immediately receive a controller faults error message that it doesn’t have license/subscription information, so we need to add it.
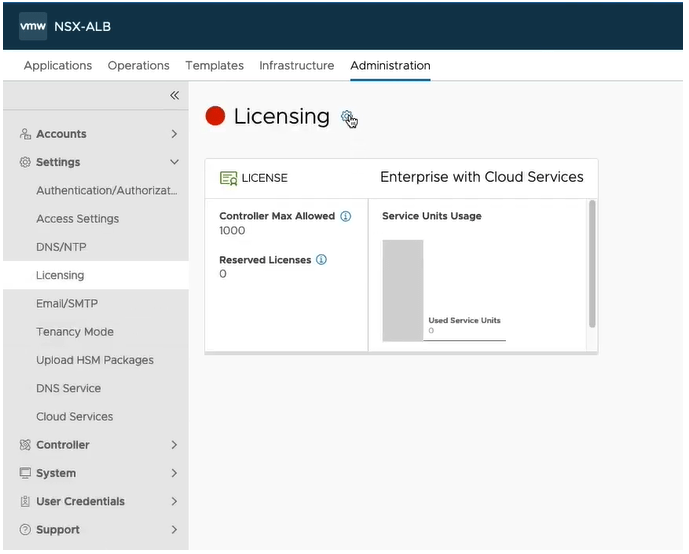
Click the Administration tab, and then on the left, expand Settings, and click Licensing. Click the gear.
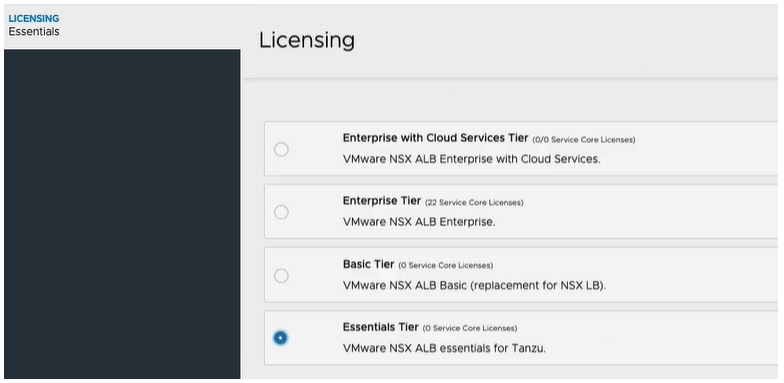
Select the Essentials Tier for Tanzu license. Click SAVE.
You can see the interface has changed, and it wants us to add a license key, however we are in the essentials mode, and can only use essentials features. We do not need to change anything.
That covers the basic deployment for the NSX-ALB controller. In my next blog, I will walk through the process of assigning a signed certificate from my Microsoft CA to the controller. I will also show how to create and assign the self-signed certificate to the controller. Stay tuned.
Blog Date: August 11, 2022 NSX-ALB Controller version: 22.1.1 vSphere version 7.0.3 Build 20150588
VMware Customers can find additional details on system design options and preparation tasks in the vSphere 7 with Tanzu Prerequisites and Preparations Guide. This blog is a summary focused on requirements when using vSphere Networking and NSX-ALB Load Balancing Controller, and the deployment of the controller. This example is for the the deployment of the controller without NSX (NSXT).
Hardware Requirements
vSphere Cluster
No. of Hosts
CPU Cores Per Host
Memory Per Host
NICs Per Host
Shared Datastore
Minimum Recommended
3
16 (Intel CPU Only)
128GB
2x 10GbE
2.5 TB
Note: Increasing the number of hosts eases the per-host resource requirements and expand the resource pool for deploying additional or larger Kubernetes clusters, applications, other integrations, etc.
To mitigate deployment delays from troubleshooting infrastructure-related problems, customers need to preconfigure both NICs with the appropriate network access, as detailed in the table below, and test for connectivity in advance of any on-site work.
VLAN Description
Host vmnic(s)
Virtual Switch
MTU
IPv4 CIDR Prefix
Routable
Management Network*
NIC 1 & 2
vDS
≥≥1500
≥≥ /27
Yes
vMotion Network**
NIC 1 & 2
vDS
≥≥1500
≥≥ /29
No
Storage / vSAN Network
NIC 1 & 2
vDS
≥≥1500
≥≥ /29
No
Workload Network***
NIC 1 & 2
vDS
≥≥1500
≥≥ /24
Yes
Data Network
NIC 1 & 2
vDS
≥≥1500
≥≥ /24
Yes
* If the ESXi hosts’ mgmt vmkNIC and other core components such as vCenter operate on separate networks, the two networks must be routable.
** As opposed to a separate network, vMotion can operate on a shared network with ESXi hosts’ mgmt vmkNIC
*** The workload network hosts K8s control plane and worker nodes
When choosing the vSphere Networking model, all network segments and routed connectivity must be provided by the underlying network infrastructure. The Management network can be the same network used for your standard vCenter and ESXi VMKernel port functions, or a separate network with full routed connectivity. Five consecutive IP addresses on the Management network are required to accommodate the Supervisor VMs, and one additional IP is required for the ASX ALB controller. The Workload CIDRs in the table above account for the typical number of IP addresses required to interface with the physical infrastructure and provide IP addresses to Kubernetes clusters for ingress and egress communications. If the CIDR ranges for Workload and Frontend functions are consolidated onto a single segment, they must be different ranges and non-overlapping.
Additionally, the Workload Management enablement will default the IP address range for Kubernetes pods and internal services to 10.96.0.0/23. This range is used inside the cluster and will be masked behind the load balancer from the system administrators, developers, and app users. This range can be overridden if needed but should remain a minimum of a /24.
Tanzu Mission Control (if available):
TKG cluster components use TCP exclusively (gRPC over HTTP to be specific) to communicate back to Tanzu Mission Control with no specific MTU outbound requirements (TCP supports packet segmentation and reassembly).
Firewall Requirements
VMware HIGHLY RECOMMENDS unfiltered traffic between networks for the system. Reference the VMware vSphere 7 with Kubernetes Prerequisites and Preparations Guide for the summary firewall requirements.
If Tanzu Mission Control (TMC) is available, the platform needs internet access connectivity.
Storage
You will need to use vSphere supported shared storage solution. Typically, this is vSAN, NFS, iSCSI or Fibre Channel. Shared storage is required. Presenting storage volumes directly is not.
Enterprise Service Requirements
DNS: System components require unique resource records and access to domain name servers for forward and reverse resolution
NTP: System management components require access to a stable, common network time source; time skew < 10 seconds
AD/LDAP (Optional): Service bind account, User/Group DNs, Server(s) FQDN, and port required for authentication with external LDAP identity providers
DRS and HA need to be enabled in the vSphere cluster.
With the above mentioned requirements in mind, after the environment prep has been completed, I like to fill out the following excel with all of the information needed for the deployment and configuration of the NSX-ALB controller.
That covers the basic requirements and prep work for the NSX-ALB controller deployment. In my next blog: vSphere with Tanzu: Deployment of NSX-ALB Controller, I will walk through the basic deployment of the controller.
On engagements with customers, I’ll have them deploy a developer VM where we can work and I can get them started on their Tanzu and Kubernetes journey. This one VM will have docker, docker credential helper, and the Tanzu Kubernetes CLI installed. For the purpose of this blog series, I’ll do the same. For this blog, I’ll walk through the process using Ubuntu 22.04. In my lab, I have already configured my Ubuntu VM with a static IP and host name.
Getting Started with Ubuntu and Installing Docker
Docker is available for download and installation on Ubuntu 22.04. To get started, let’s update the package repo first, and then we can install docker.
$ sudo apt update
$ sudo apt install docker.io
After the Docker installation has completed successfully, let’s start the Docker service, and enable it to run on boot.
Let’s run the following command to see the Docker path. We should get a return /usr/bin/docker
$ which docker
Let’s make sure Docker is running with the following command.
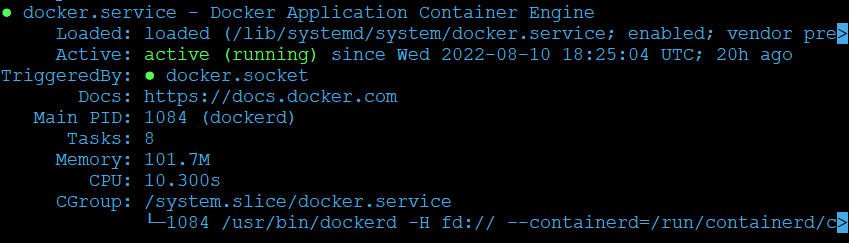
$ sudo systemctl status docker
We should see an active (running) status.
You can verify the current Docker version installed, and see additional details with the following command.
$ sudo docker version
At this point, my customer would have completed to per-requisite to have an Ubuntu VM deployed for me. In this blog however, I will continue on assuming vSphere with Tanzu has already been enabled on a workload cluster in the environment.
Downloading The Kubernetes CLIvsphere-plugin.zip
The official VMware guide to Download and Install the Kubernetes CLI Tools for vSphere can be found here. In the vSphere Client, click the 3 hash marks in the upper left and select Workload Management. Select the Supervisor Clusters tab. Make note of the Control Plane Node Address (IP address). It will be needed for the next command to download the vsphere-plugin.zip.
In the example command, I am using the optional –no-check-certificate. Replace the IP address with your Control Plane Node IP Address
We are up to step 2, and we need to put the contents of the unzipped vsphere-plugin into your executable search path. Let’s execute the following commands.
Next, we’ll exit our current SSH session on the ubuntu dev vm.
$ exit
Now re-establish a SSH session to the ubuntu dev vm using the same account as before. Once logged in, let’s test that kubectl completion bash is working. We do this by entering ‘kubectl’ followed by a space and then hit tab twice.
$ kubectl
Test Connection to Tanzu Control plane (optional)
From the Ubuntu dev VM, use the kubectl CLI to connect to the vSphere with Tanzu control plane as the authenticated user. Here I am using the –insecure-skip-tls-verify optional parameter
It will prompt for a username and password. Once successfully logged in and if the account you chose has permissions to access the Tanzu control plane node, you should see a message stating you have access to the following contexts.
Now you are ready to begin working with Tanzu. More content to come. Stay tuned.
VMware vCenter Server 7.0 Update 2d used. VMware NSX-T Data Center 3.1.3.1 used.
Assumptions:
In a previous post titled vSphere with Tanzu on VMware Cloud Foundation/vSphere with NSX-T requirements, I went over the requirements I pass along to customers, along with the supporting VMware documentation, and this post assumes those requirements and those in the VMware documentation have been met. The same networking requirements exist here for standard vSphere 7 deployments with NSX-T.
Validate/Configure NSX-T IP Prefixes on the Tier-0 Gateway
Validate/Configure NSX-T Route Maps on the Tier-0 Gateway
Validate MTU greater than or equal to 1600 on all networks that will carry Tanzu traffic i.e. management network, NSX Tunnel (Host TEP, Edge TEP) networks, and the external network.
In the vSphere Client, select Menu > Workload Management.
Click Get Started. (The Enable Workload Management wizard opens.)
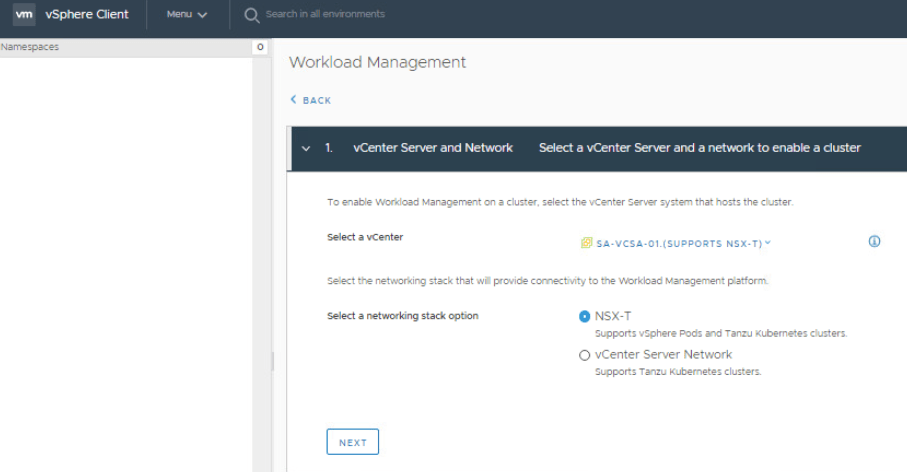
On the vCenter Server and Network section, select NSX-T. Click Next.
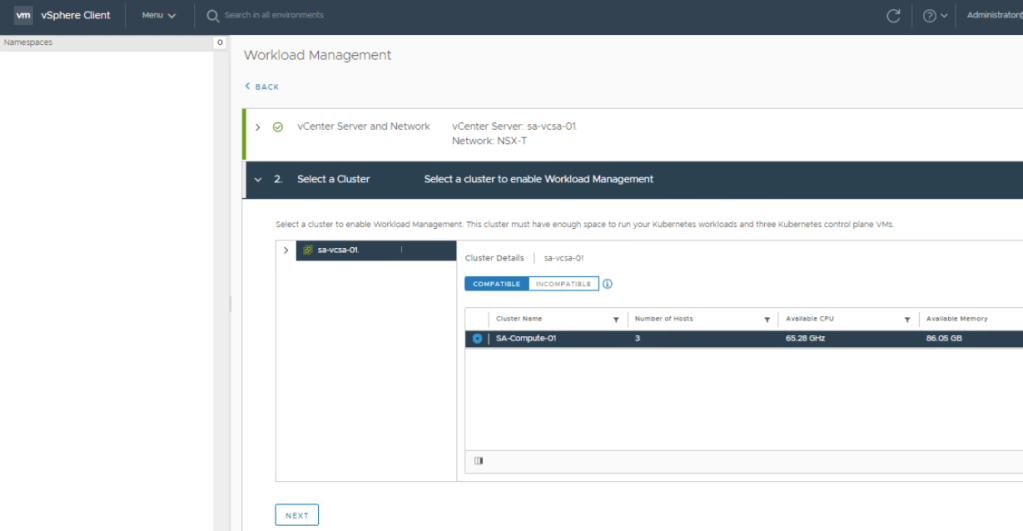
On the Select a Cluster section, select the ESXi cluster to support vSphere with Tanzu.
Next, select the size of the control plane. Click Next.
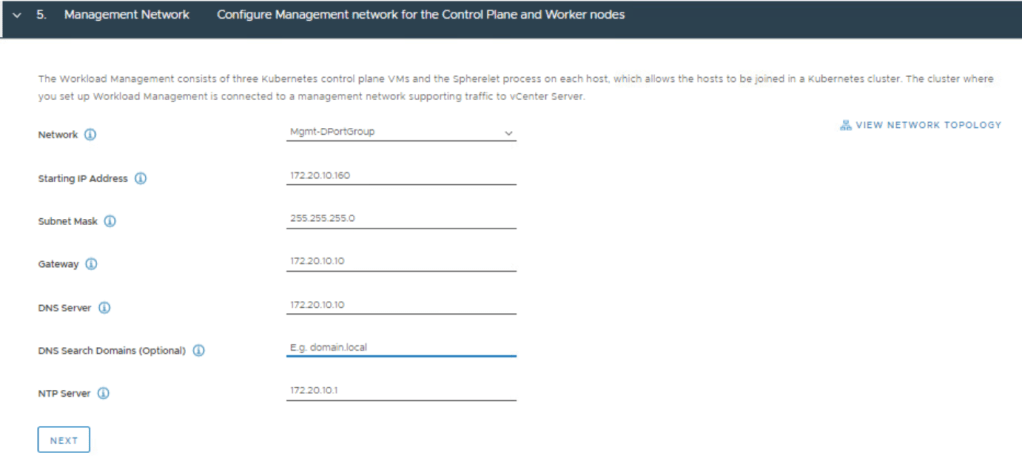
Fill in the Management Network details.
Scroll down, and fill in the Workload Network details. As mentioned in a previous post, I will argue that the API Server endpoint FQDN entry is mandatory when applying a certificate. NOTE: The Pod and Service CIDRs are non-routable. The UI provides default values that can be used, otherwise you specify your own. The Ingress and Egress CIDRs will be routable networks defined by the network team. Click Next.
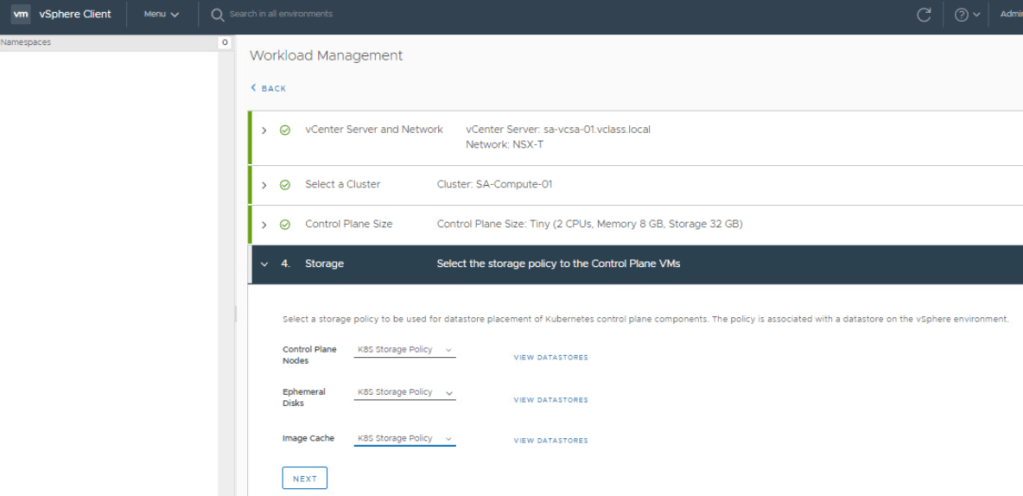
Select the storage policy for Control Plane Nodes, Ephemeral Disks, Image cache. vSAN Default Storage Policy can be used if only storage/cluster provided. Click Next.
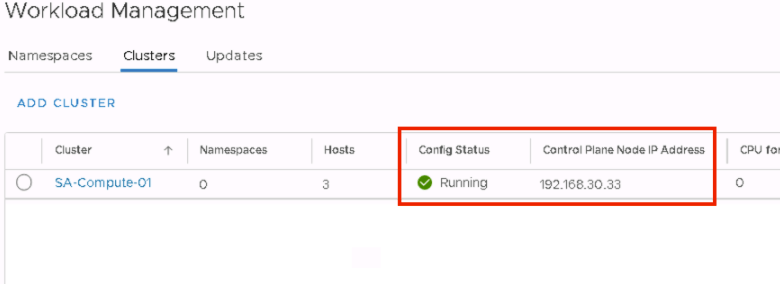
That’s it. Click Finish. The Tanzu deployment will now proceed (The entire process can take up to 45 minutes to complete).
The Control Plane Node IP address is the same API Server Endpoint we referred to earlier in this post. This will be the end point where you can download and install the vSphere plugin and the vSphere docker credential helper. To validate connectivity, simply open a web browser and go to the IP address http://<ip-address>
If you are not able to reach the Control Plane Node IP address/API Server Endpoint, it is possible that you might have invalid MTU settings in your environment that will require further troubleshooting. I did come across this at a customer site, and documented the MTU troubleshooting process here. Good luck.
Blog Date: December 5, 2021 Updated: August 8, 2022 VMware Cloud Foundation 4.3.1 used. VMware vCenter Server 7.0 Update 2d used. VMware NSX-T Data Center 3.1.3.1 used. VMware Photon OS 3.0
On engagements with customers, I’ll have them deploy a developer VM where we can work and I can get them started on their Tanzu and Kubernetes journey. This one VM will have docker, docker credential helper, and the Tanzu Kubernetes CLI installed. For the purpose of this blog series, I’ll do the same.
Getting Started with Photon OS and Installing Docker
The first step was to deploy the Photon OS ova: https://github.com/vmware/photon/wiki. This URL has all of the instructions on getting started as well as running Docker which only requires two commands:
The Docker service needs to be set up to run at startup. To do so, input the following commands:
$ sudo systemctl start docker
$ sudo systemctl enable docker
(Optional) Once that completes, run the following commands to allow docker to run as non-root:
$ sudo groupadd docker
$ sudo usermod -aG docker $USER
$ newgrp docker
The following command will start docker if it is not already running. Likewise you can do a status instead of a start:
$ systemctl start docker
Downloading The Kubernetes CLI
First, if this is going to be a shared box, it will be a good idea to create a directory where we can place the files:
$ mkdir -p /opt/vsphere-plugin
If needed you can locate the control plane node IP address from the workload management section in vSphere.
The Kubernetes CLI can be downloaded from the https:// via wget.
Select the vCenter cluster where Workload Management and the embedded Harbor Registry are enabled. – Select Configure > Namespaces > Image Registry. – In the Root certificate field, click the link Download SSL Root Certificate. – Save the root-certificate.txt, and rename it to something like ca.crt.
Copy the embedded Harbor Registry ca.crt file that you downloaded to the /etc/docker/certs.d/IP-address-of-harbor/ created in the previous step.
That directory should now look something like:
/etc/docker/certs.d/IP-address-of-harbor/ca.crt
Restart the docker service so that the new certificate is used:
$ systemctl restart docker
To test that the docker credential helper is working, you can log into the embedded harbor registry using your fully qualified domain credentials. As long as you don’t get a certificate trust error, you are good to go.
$ docker-credential-vsphere login <harbor_ip>
This blog should have prepped the Developer VM (Photon OS) that we will be using going forward. There will be a future blog post on pushing a docker image to the embedded harbor registry, but I am not going to cover this here. In my next post, I’ll walk through the steps of installing a Tanzu Kubernetes Cluster inside the namespace we deployed using this VM. Stay tuned.












































You must be logged in to post a comment.