Note: To use the embedded Harbor Registry, you must deploy the Supervisor Cluster with NSX-T Data Center as the networking solution.
Procedure:
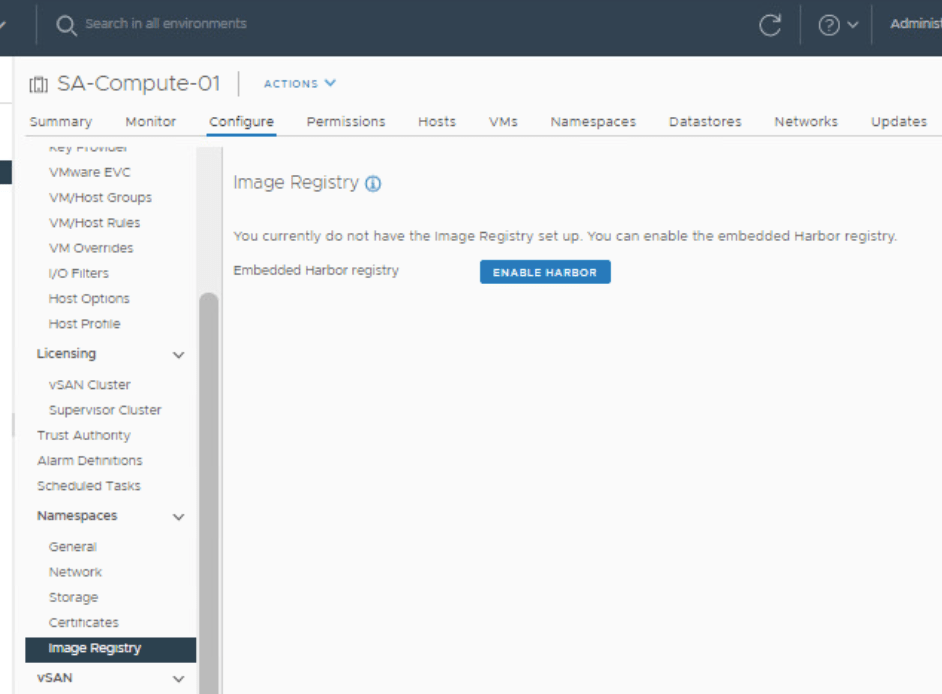
In the vSphere client/workload domain that has Tanzu deployed, select the compute cluster, click on the configure tab, and then in the center menu, scroll down until you find Namespaces. Under Namespaces, select “Image Registry”.
Click Enable Harbor.
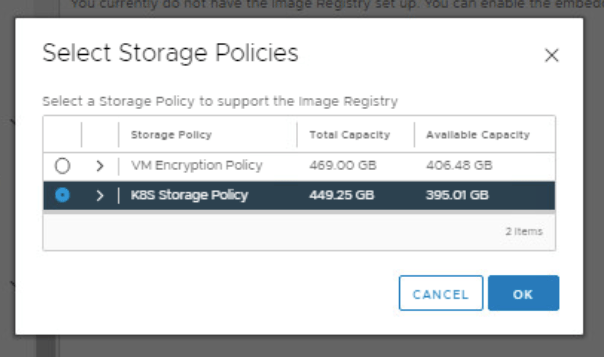
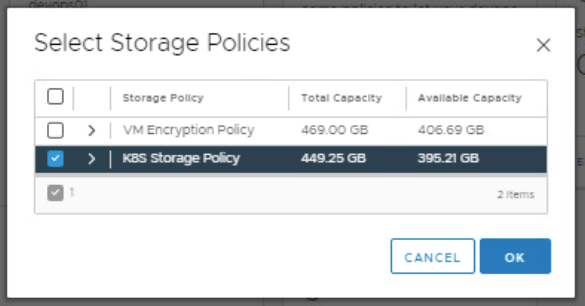
In the Select Storage Policies window, select K8S Storage Policy and click OK
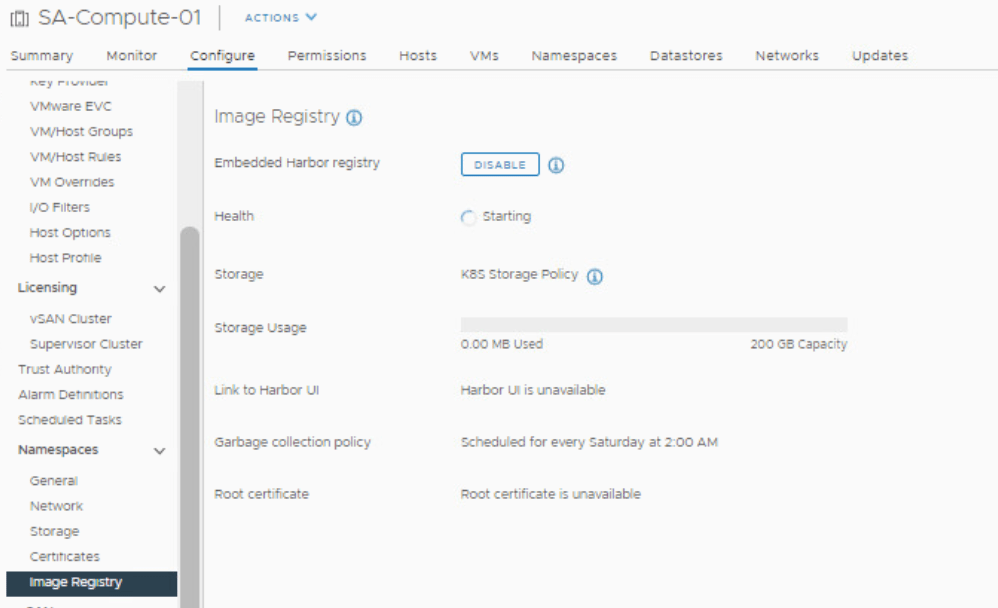
The embedded Harbor Registry begins deploying.
The deployment can take up to 20 minutes depending on how large the cluster is, but I have seen the deployment take less than 10 minutes for small clusters of four.
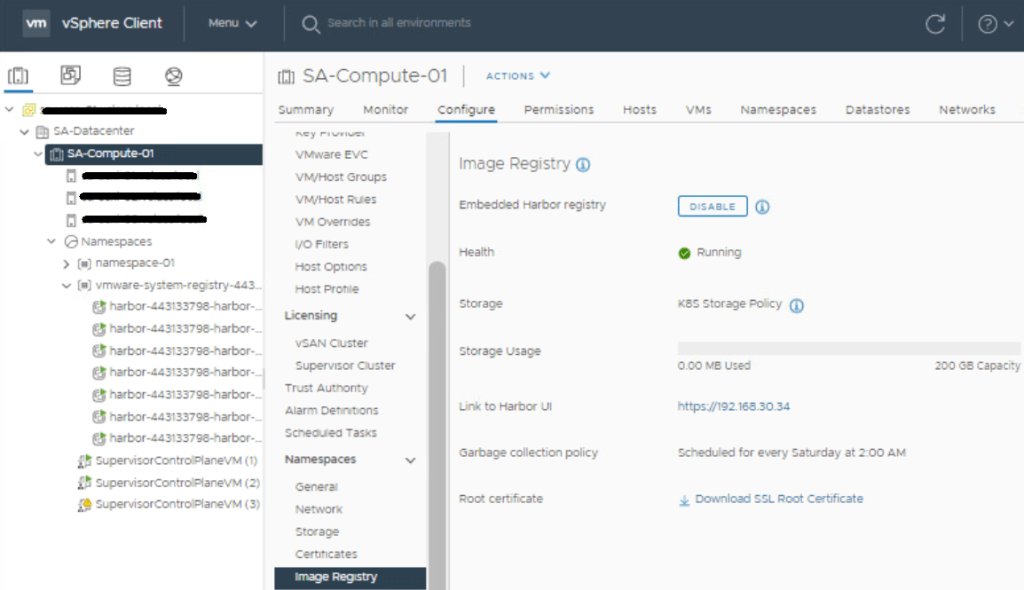
You’ll find the IP address and link to the Harbor UI on this page once the deployment completes. We’ll come back to this in a later post. If you’d like, you can log into the harbor registry UI with the user and or group account that was defined in the namespace permissions section.
In my next post, I’ll go over the steps of getting the Ubuntu VM ready, which I will either refer to as the developer box or developer workstation. We’ll get docker installed, the vsphere plugin which has the Kubernetes cli, and the docker credential helper to start with. Later on we’ll also install some TKG extensions like helm, kapp, and ytt.
Access the vSphere client. Select Menu > Workload Management > Namespaces.
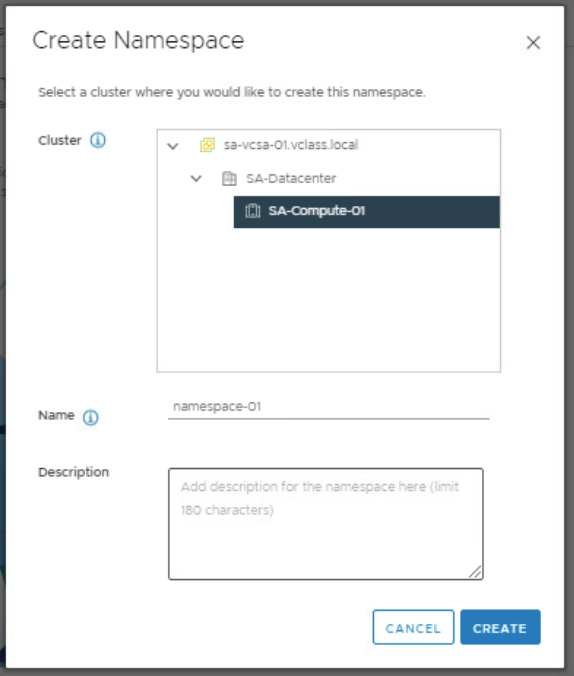
Click CreateNamespace.
Expand the inventory tree and select the compute cluster.
As am example, you can enter namespace-01 as your namespace name. (The name must be in a DNS-compliant format (a-z, 0-9, -)).
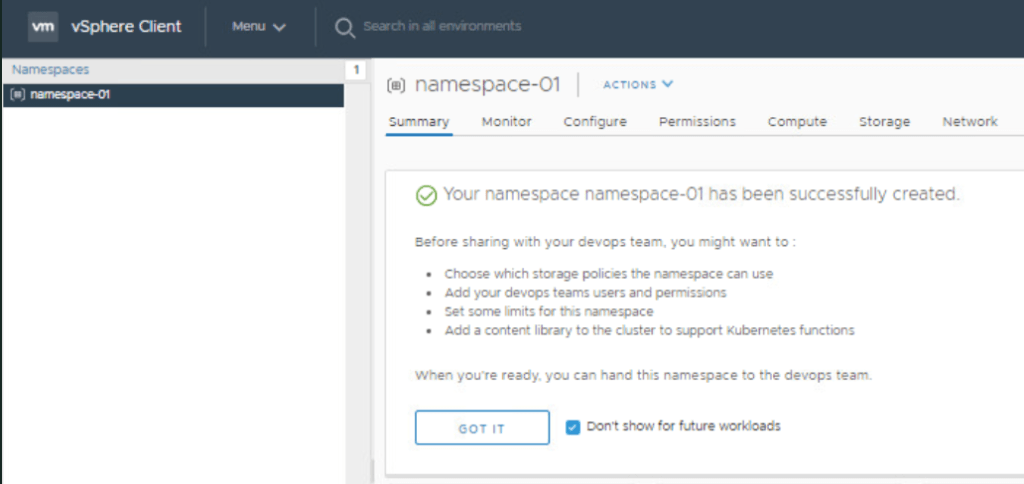
Click Create. ( The namespace is created and shows a Config Status of Running and a Kubernetes Status of Active.)
Select the Don’t show for future workloads check box.
Click Got It.
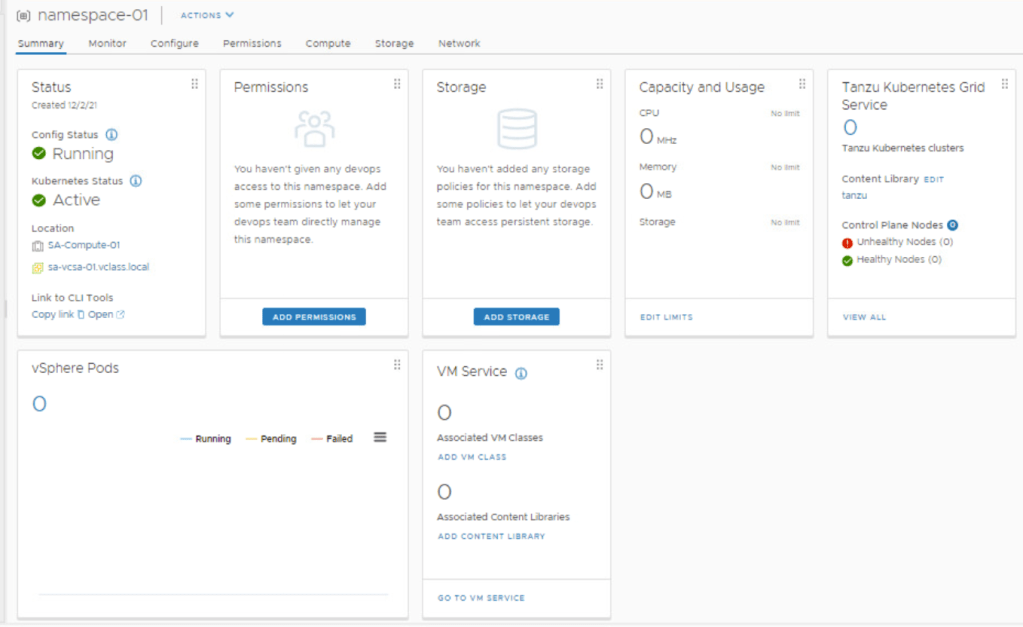
Now we can move on to the next section and apply permissions, storage and VM class.
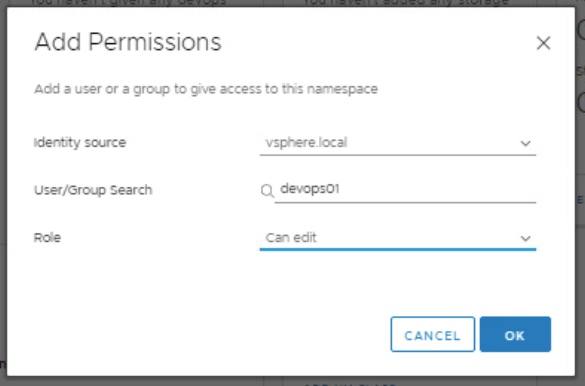
Click Add Permissions
Identity source: <make selection>
User/Group Search: <customer specific>. In this example, I have created a vsphere.local account. You can easily use an active directory account or group here.
Role: <customer specific>. In this example, I have chosen “can edit” that way I can create and destroy things inside the namespace.
Click Ok
(Rinse-wash-repeat as necessary)
Click Add Storage and add the storage policy.
The namespace is configured with a storage policy and user permissions. The assigned storage policy is translated to a Kubernetes storage class.
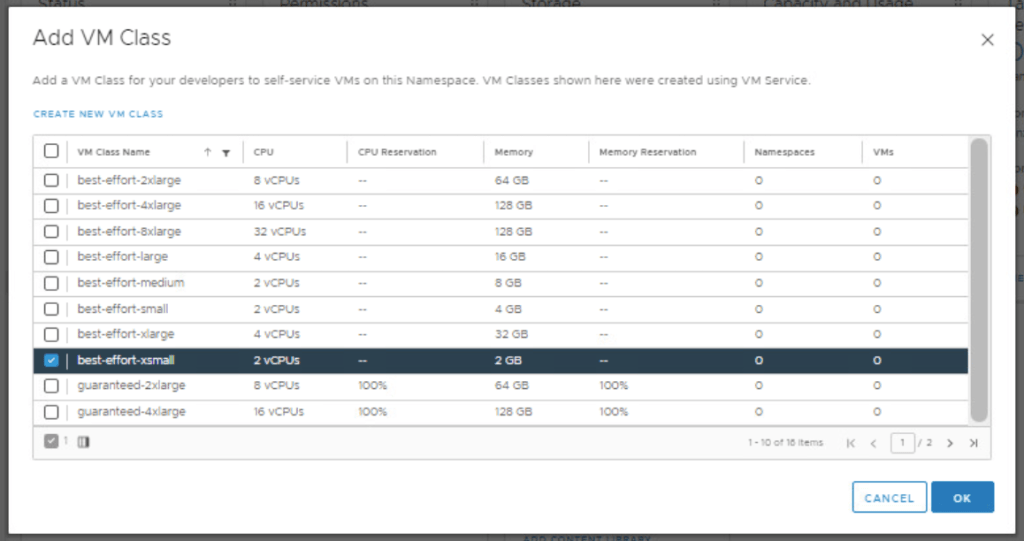
Under VM Service, click Add VM Class. Here we need to associate a VM class with the namespace, that will allow developers to self-service VMs in the namespace. This gives vSphere administrators flexibility with resources available in the cluster. In this example, best-effort-xsmall was chosen because this is a nested lab environment. You should work with your developers to determine the best sizing strategy for the containerized workloads.
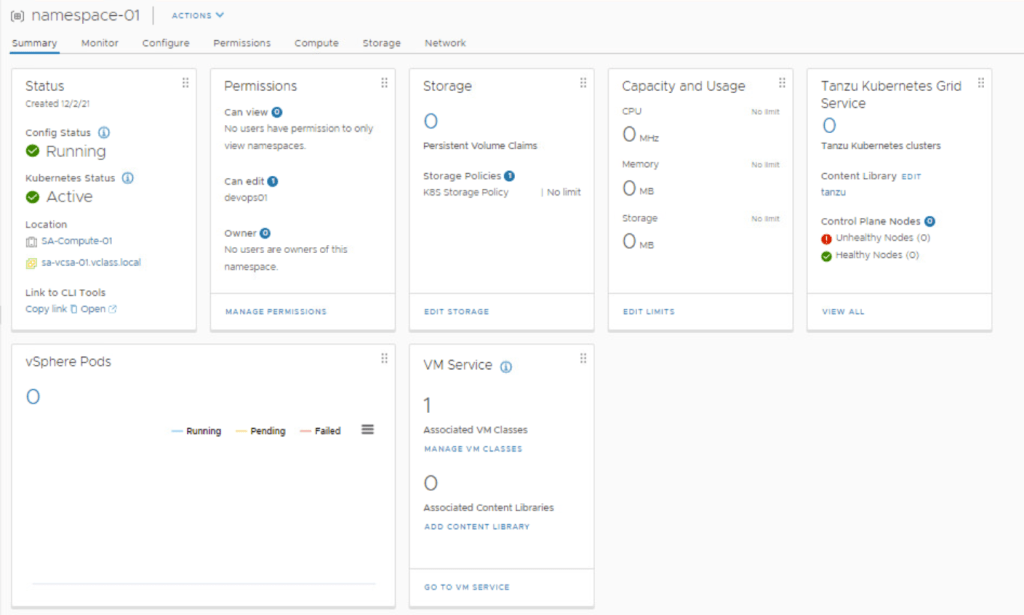
Now that the Namespace, Storage, and VM Class policies have all been defined, your window should look something like:
Validate/Configure NSX-T IP Prefixes on the Tier-0 Gateway
Validate/Configure NSX-T Route Maps on the Tier-0 Gateway
Validate MTU greater than or equal to 1600 on all networks that will carry Tanzu traffic i.e. management network, NSX Tunnel (Host TEP, Edge TEP) networks, and the external network.
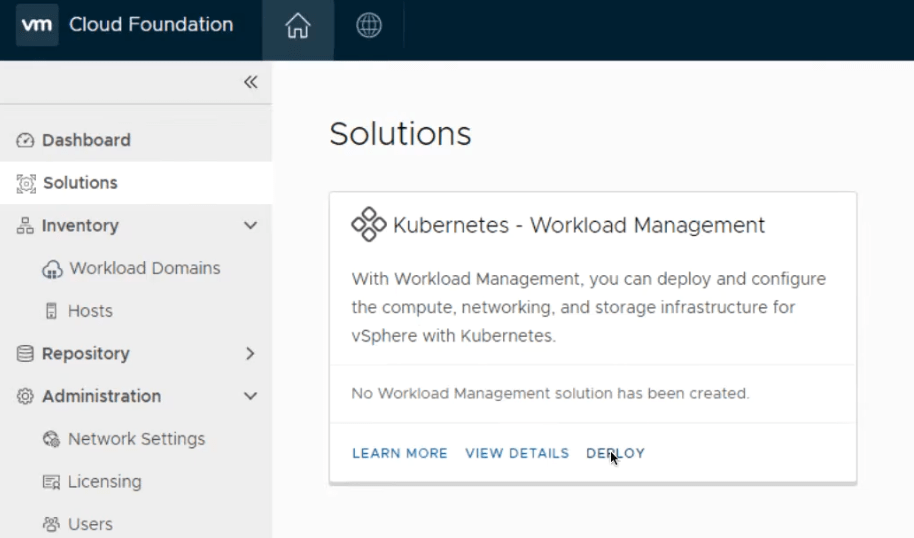
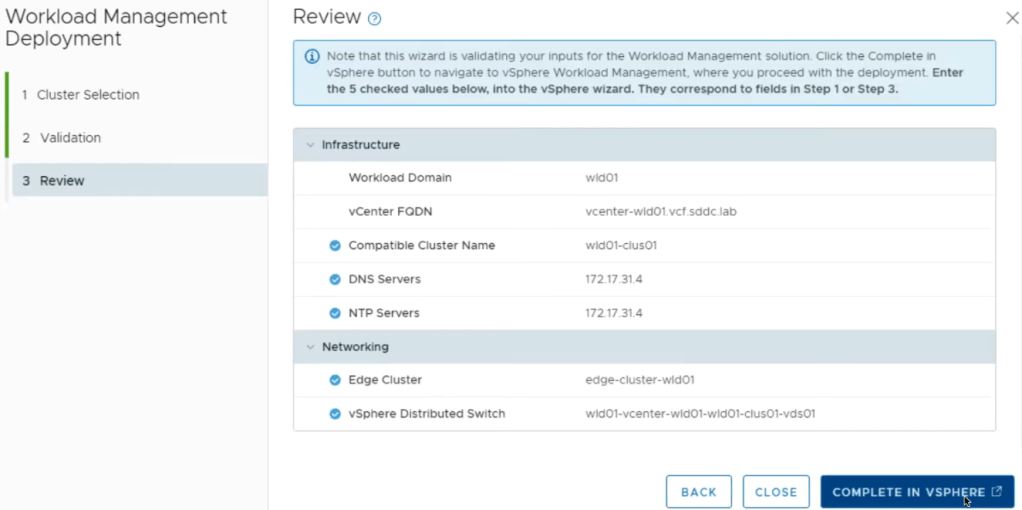
After you have configured VM (storage) policies in vSphere and added segments in NSX-T Data Center, you can deploy vSphere with Tanzu. SDDC Manager first validates your environment then redirects you to the vSphere Client where you complete the deployment. From the SDDC manager UI, navigate to Solutions and select Deploy.
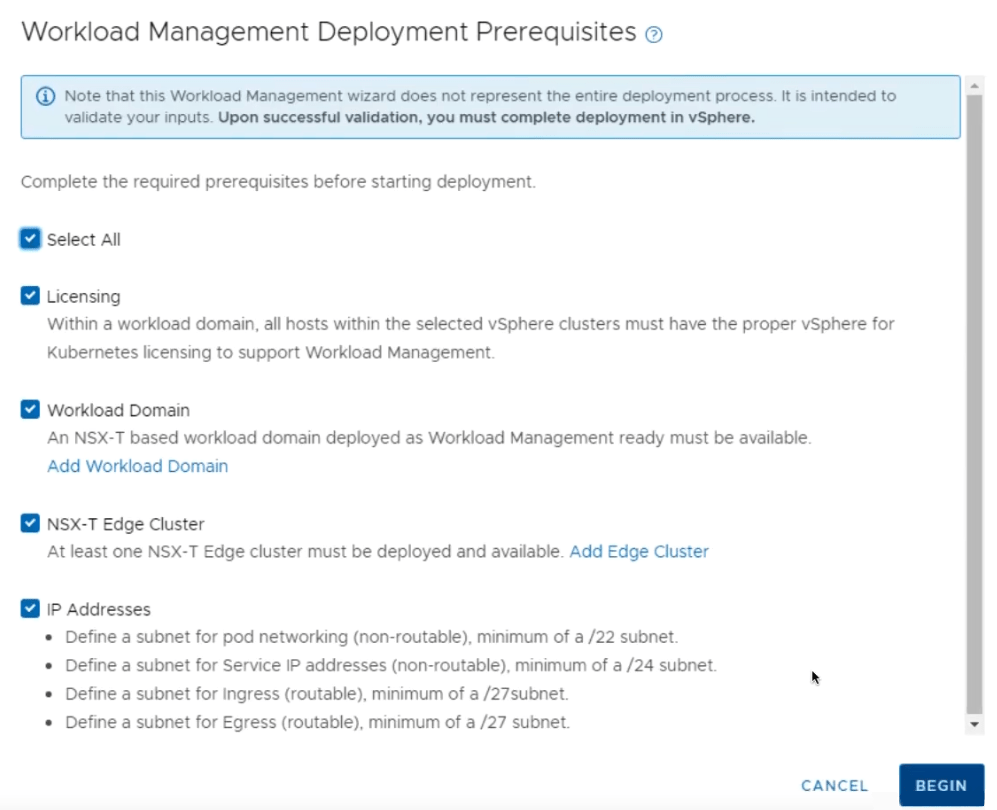
Select All to have SDDC manager run a deployment prerequisites check. Click Begin.
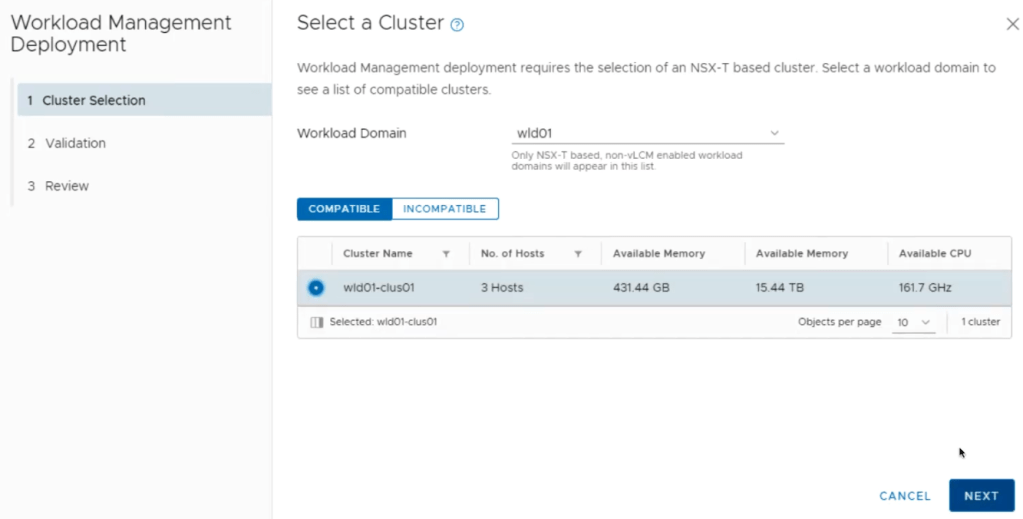
Select the desired cluster for the Tanzu workload. Click Next.
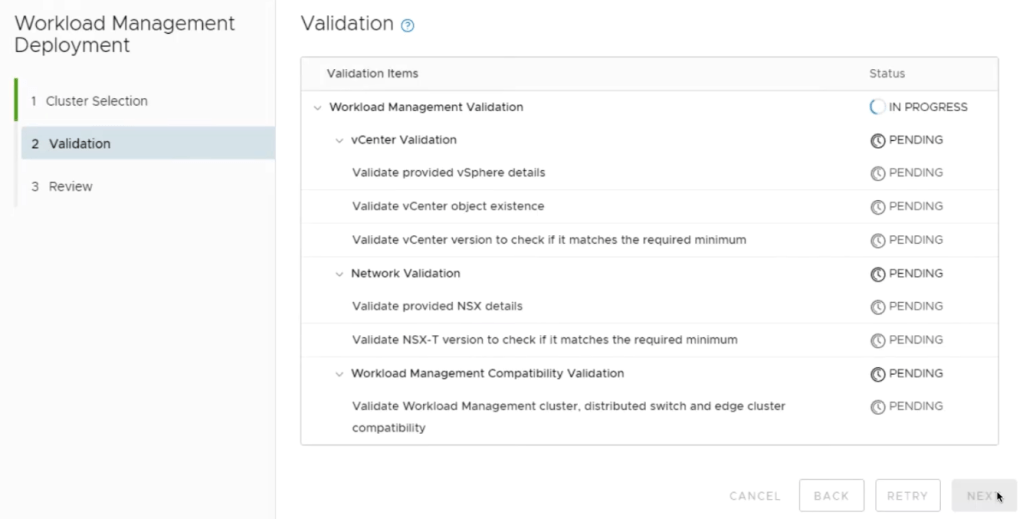
The SDDC manager will begin running the Validation. All Statuses should succeed . Else troubleshoot/Retry. Click Next.
After successful validation, SDDC will switch you over to the vSphere client to complete the deployment.
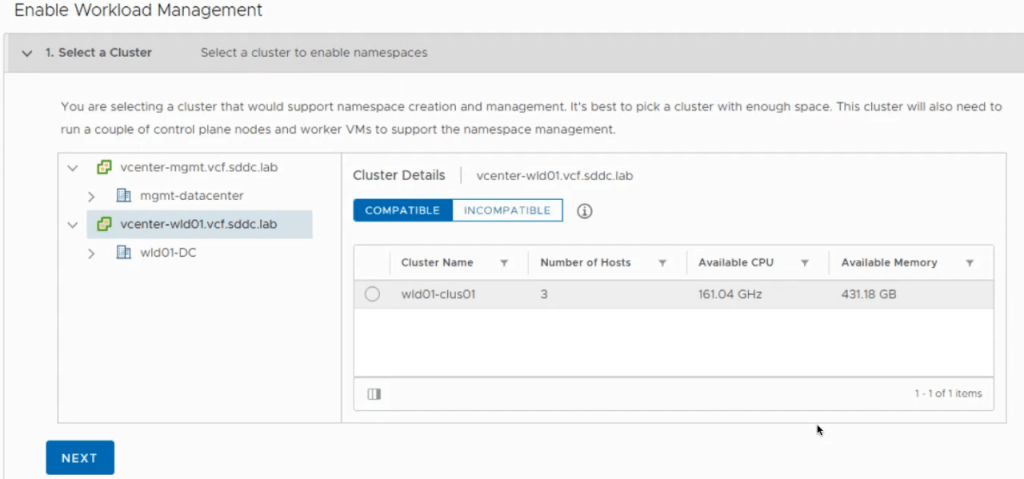
In the vSphere client, select the desired cluster to enable Tanzu. Click Next.
Next, select the size of the control plane. Click Next.
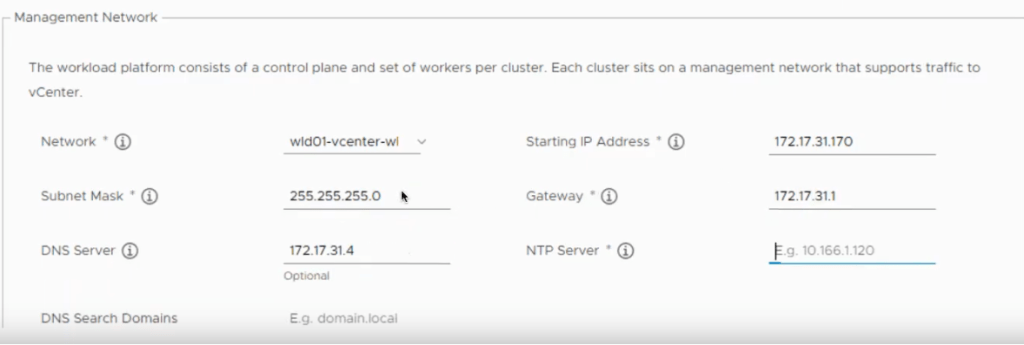
Fill in the Management Network details.
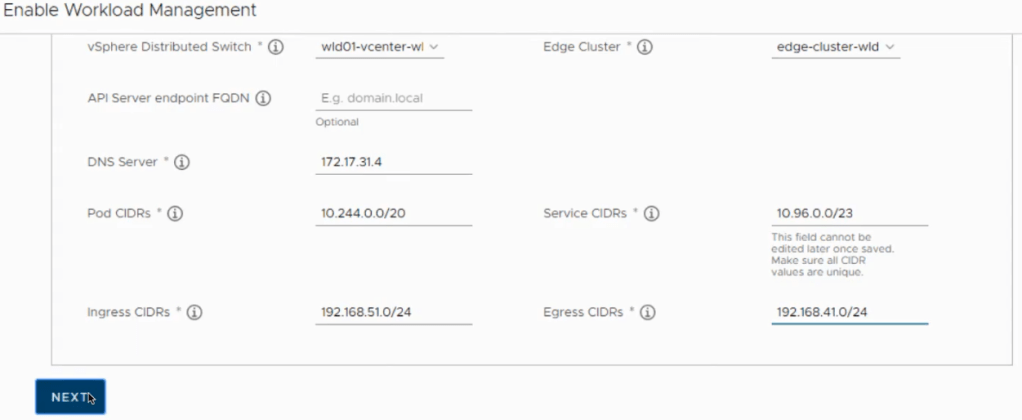
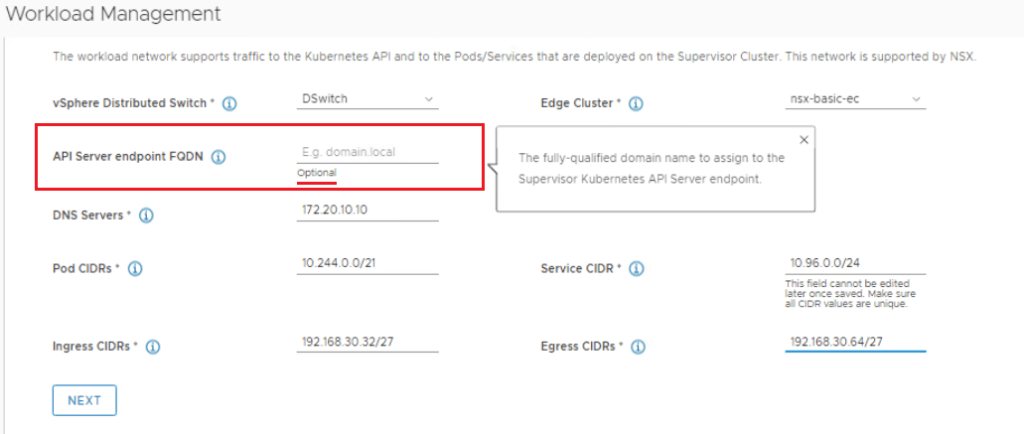
Scroll down, and fill in the Workload Network details. As mentioned in a previous post, I will argue that the API Server endpoint FQDN entry is mandatory when applying a certificate. NOTE: The Pod and Service CIDRs are non-routable. The UI provides default values that can be used, otherwise you specify your own. The Ingress and Egress CIDRs will be routable networks defined by the network team. Click Next.
Select the storage policy for Control Plane Nodes, Ephemeral Disks, Image cache. vSAN Default Storage Policy can be used if only storage/cluster provided. Click Next.
That’s it. Click Finish. The Tanzu deployment will now proceed (The entire process can take up to 45 minutes to complete).
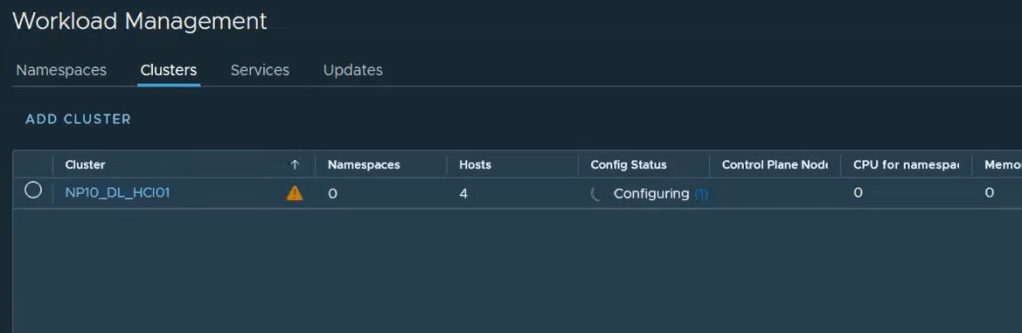
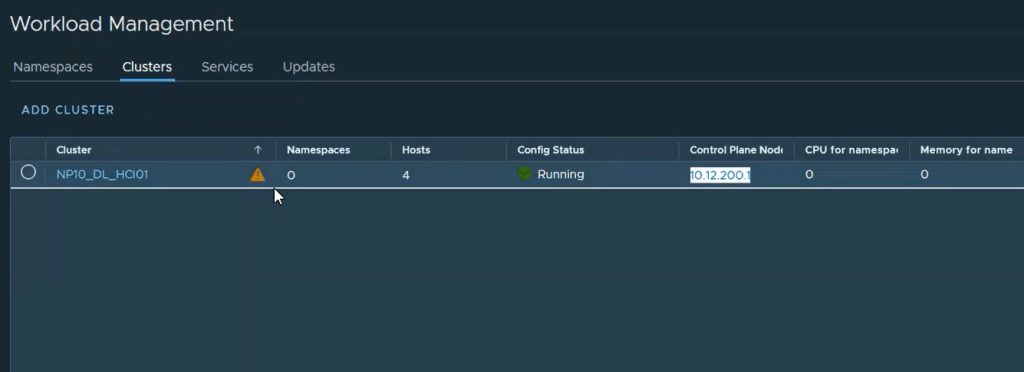
One the process is complete, we will see a config status of running with a green check. The cluster will have a yellow triangle because we have not assigned a license yet.
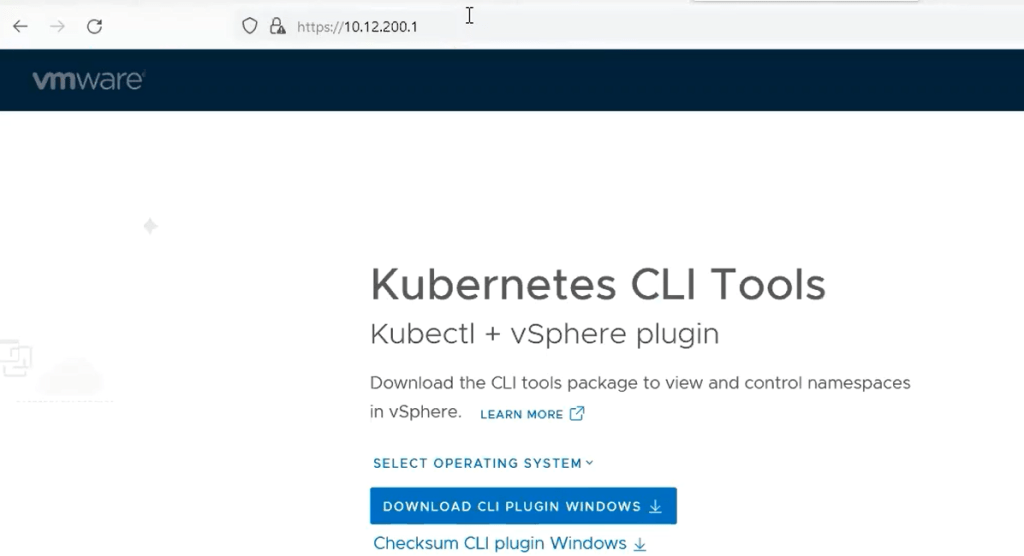
The Control Plane Node IP address is the same API Server Endpoint we referred to earlier in this post. This will be the end point where you can download and install the vSphere plugin and the vSphere docker credential helper. To validate connectivity, simply open a web browser and go to the IP address http://<ip-address>
From here, you can download the CLI plugin for windows.
If you are not able to reach the Control Plane Node IP address/API Server Endpoint, it is possible that you might have invalid MTU settings in your environment that will require further troubleshooting. I did come across this at a customer site, and documented the MTU troubleshooting process here. Good luck.
VMware Cloud Foundation 4.3.1 Used During Deployment:
Summary requirements:
– For VMware Cloud Foundation 4.3.1 software requirements, please refer to the Cloud Foundation Bill of Materials (BOM) – For vSphere with Tanzu, it is recommended to have at least three hosts with 16 CPU Cores per host (Intel), 128GB per host, 2x 10GBe Nics per host, and a shared datastore of at least 2.5 TB. – This post assumes VCF 4.3.1 has already been deployed following recommended practices.
System Requirements for Setting Up vSphere with Tanzu with NSX-T Data Center
The following link to VMware’s documentation should be reviewed prior to installation of Tanzu. This link includes networking requirements. Tanzu with NSX-T Data Center Requirements
Specific Tanzu Call-outs:
IP Network
POD CIDR
Services CIDR
Ingress CIDR
Egress CIDR
Management Network
IPv4 CIDR Prefix
Greater than or equal to /20
Greater than or equal to /22
Greater than or equal to /24
Greater than or equal to /24
5 consecutive IPs
Justification:
POD CIDR: Dedicate a /20 subnet for pod networking. Private IP space behind a NAT that you can use in multiple Supervisor Clusters.Note: when creating TKG clusters, the IP addresses used for the K8s nodes are also allocated from this IP block. Services CIDR: Dedicate a /22 subnet for services. Private IP space behind a NAT that you can use in multiple Supervisor Clusters. Ingress CIDR: TKGS sources the ingress CIDR for allocating routable addresses to the Kubernetes clusters’ API VIP, ingress controller VIP, and service-type Load-Balancer VIP(s). Note: This subnet must be routable to the rest of the corporate network. Egress CIDR: TKGS sources the egress CIDR to enable outbound communication from namespace pods. NSX-T automatically creates a source network address translation (SNAT) entry for each namespace, mapping the pod network to the routable IP address, respectively. Note: This subnet must be routable to the rest of the corporate network Management Network: Five consecutive IP addresses on the Management network are required to accommodate the Supervisor VMs. MTU: Greater than or equal to 1600 on all networks that will carry Tanzu traffic i.e. management network, NSX Tunnel (Host TEP, Edge TEP) networks, and the external network.
Note: Kubernetes cluster requires identifying private IPv4 CIDR blocks for internal pod networks and service IP addresses. The Pods CIDR and Service CIDR blocks cannot overlap with IPs of Workload Management components (vCenter, ESXi hosts, NSX-T components, DNS, and NTP) and other data center IP networks communicating with Kubernetes pods. The minimum Pods CIDR prefix length is /23, and the minimum Service CIDR prefix length is /24.
Also: If using Tanzu Mission Control, TKG cluster components use TCP exclusively (gRPC over HTTP to be specific) to communicate back to Tanzu Mission Control with no specific MTU outbound requirements (TCP supports packet segmentation and reassembly).
Deploy an NSX-T Edge Cluster
The following link to VMware’s documentation should be reviewed, and can be used to deploy the necessary NSX Edge Cluster prior to the Tanzu deployment. Deploy an NSX-T Edge Cluster
Enterprise Service Requirements
DNS: System components require unique resource records and access to domain name servers for forward and reverse resolution.
NTP: System management components require access to a stable, common network time source; time skew < 10 seconds.
DRS and HA: Need to be enabled in the vSphere cluster
(Useful but Optional): Ubuntu developer VM with docker installed for use while interacting with Tanzu.
Blog Date: June 25, 2021 Tested on vSphere 7.0.1 Build 17327586 vSphere with Tanzu Standard
On a recent customer engagement, we ran into an issue where after we deployed project Contour, and created a TLS delegation “contour-tls”, but we ran into an issue where Contour did not like the public wildcard certificate we provided. We were getting an error message “TLS Secret “projectcontour/contour-tls” is invalid: Secret not found.”
After an intensive investigation to make sure everything in the environment was sound, we came to the conclusion that the “is invalid” part of the error message suggested that there was something wrong with the certificate. After working with the customer we discovered that they included the Root, the certificate, and the intermediate authorities in the PEM file. The root doesn’t need to be in the pem. Just the certificate, and the intermediate authorities in descending order. Apparently that root being in the pem file made Contour barf. Who knew?
You could possibly see that the certificate is the issue by checking the pem data for both the <PrivateKeyName>.key and the <CertificateName>.crt by running the following commands, and comparing the pem output. IF it doesn’t match this could be your issue as well. The “<>” should be updated with your values, and don’t include these “<” “>”.
Below are the troubleshooting steps we took, and what we did to resolve the issue. We were using Linux, and had been logged into vSphere with Tanzu already. Did I mention that I hate certificates? But I digress….
The Issue:
You had just deployed a TKG cluster, and then deployed Project Contour as the ingress controller that uses a load balancer to be the single point of entry for all external users. This connection terminates SSL connections, and you have applied a public wildcard certificate to it. You created the TLS secret, and have created the TLS delegation, so that new apps deployed to this TKG cluster can delegate TLS connection terminations to contour. However, after you deployed your test app to verify the TLS delegation is working, you see a status of “Invalid. At least one error present, see errors for details.”, after running the following command:
kubectl get httpproxies
Troubleshooting:
You run the following command to gather more information, and see in the error message: “Secret not found” Reason: “SecretNotValid“
kubectl describe httpproxies.projectcontour.io
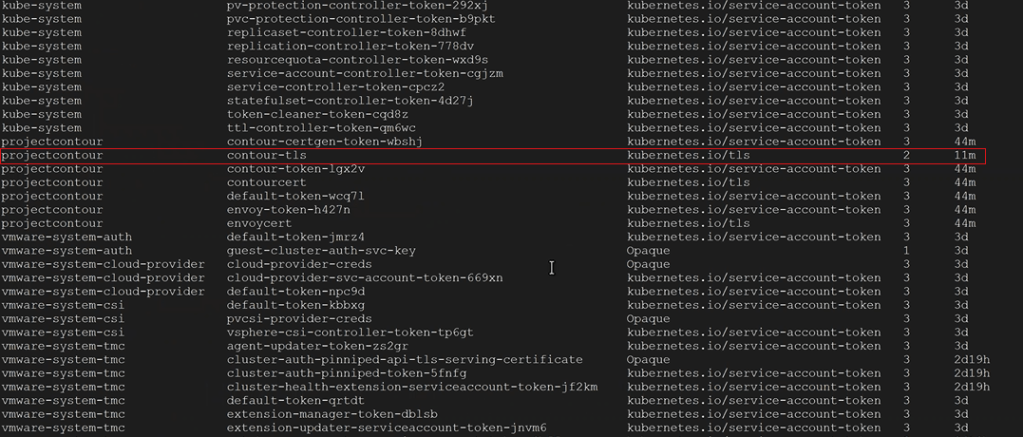
2. You check to make sure the TLS Secret was created in the right namespace with the following command, and you see that it is apart of the desired namespace. In this example, our namespace was called projectcontour, and the TLS secret was called contour-tls.
kubectl get secrets -A
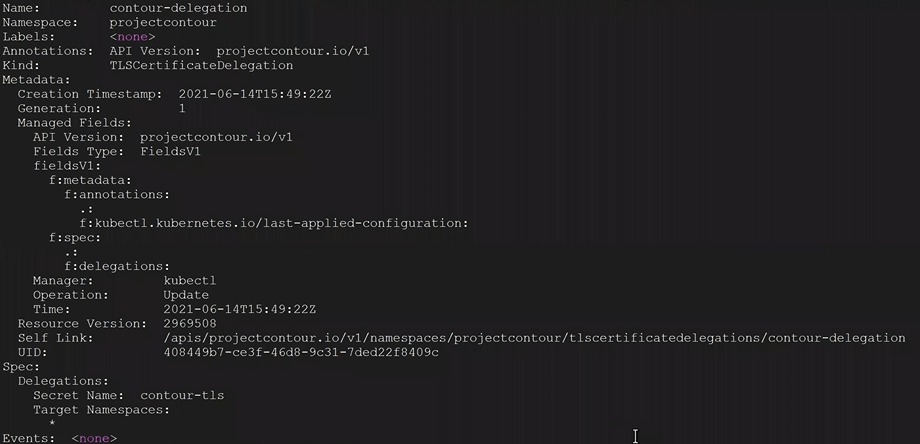
3. You check the TLS delegation to make sure it was created with the following command. In this example ours was called contour-delegation, and our namespace is projectcontour.
kubectl get tlscertificatedelegations -A
4. You look at the contents of the tlscertificatedelegations with the following command, and nothing looks out of the ordinary.
kubectl describe tlscertificatedelegations -A
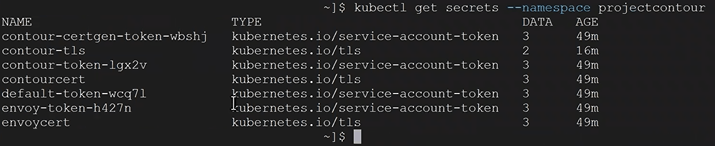
5. You check to see the secrets of the namespace with the following command. In this example our namespace is called projectcontour and we can see our TLS delegation contour-tls.
kubectl get secrets --namespace projectcontour
6. You validate contour-tls has data in it with the following command. In this example, our namespace is projectcontour and our TLS is contour-tls.
kubectl get secrets --namespace projectcontour contour-tls -o yaml
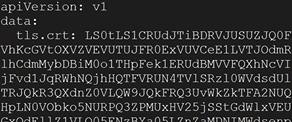
In the yaml output, up at the top you should see tls.crt: with data after
Down towards the bottom of the yaml output, you should see tls.key with data after
Conclusion: Everything looks proper on the Tanzu side. Based on the error message we saw “TLS Secret “projectcontour/contour-tls” is invalid: Secret not found.” The “is invalid” part could suggest that there is something wrong with the contents of the TLS secret. At this point, the only other possibility would be that the public certificate has something wrong and needs to be re-generated. The root doesn’t need to be in the pem. Just the certificate for the site, and intermediate authorities in descending order.
The Resolution:
Create and upload the new public certificate for contour to vSphere with Tanzu.
We’ll need to delete the secret and re-create it. Our secret was called “contour-tls”, and the namespace was called “projectcontour”.
3. We needed to clean our room, and delete the httpproxies we created in our test called test-tls.yml, and an app that was using the TLS delegation. In this example it was called tls-delegation.yml
kubectl delete -f test-tls.yml
kubectl delete -f tls-delegation.yml
4. Now we created a new secret called contour-tls with the new cert. The <> indicates you need to replace that value with your specific information. The “<>” does not belong in the command.
5. Validate the pem values for .key and .crt match. The <> indicates you need to replace that value with your specific information. The “<>” does not belong in the command.
6. If the pem numbers match, the certificate is valid. Lets go ahead an re-create the tls-delegation. Example command:
kubectl apply -f tls-delegation.yml
7. Now you should be good to go. After you deploy your app, you should be able to check the httpproxies again for Project Contour, and see that it has a valid status
kubectl get httpproxies.projectcontour.io
If all else fails, you can open a ticket with VMware GSS to troubleshoot further.
Blog Date: June 18, 2021 Tested on vSphere 7.0.1 Build 17327586 vSphere with Tanzu Standard
On a recent customer engagement, we ran into an issue where vSphere with Tanzu wasn’t successfully deploying. We had intermittent connectivity to the internal Tanzu landing page IP. What we were fighting ended up being inconsistent MTU values configured both on the VMware infrastructure side, and also in the customers network. One of the many prerequisites to a successful installation of vSphere with Tanzu, is having a consistent MTU value of 1600.
The Issue:
Tanzu was just deployed to an NSX-T backed cluster, however you are unable to connect to the vSphere with Tanzu landing page address to download Kubernetes CLI Package via wget. Troubleshooting in NSX-T interface shows that the load balancer is up that has the control plane VMs connected to it.
Symptoms:
You can ping the site address IP of the vSphere with Tanzu landing page
You can also telnet to it over 443
Intermittent connectivity to the vSphere with Tanzu landing page
Intermittent TLS handshake errors
vmkping tests between host vteps is successful.
vmkping tests from hosts with large 1600+ packet to nsx edge node TEPs is unsuccessful.
These validations should have been completed prior to the deployment. However, in this case we were finding inconsistent MTU settings. So to simplify, these are what you need to look for.
In NSX-T, validate that the MTU on the tier-0 gateway is set to a minimum of 1600.
In NSX-T, validate that the MTU on the edge transport node profile is set to a minimum of 1600.
In NSX-T, validate that the MTU on the host uplink profile is set to a minimum of 1600.
In vSphere, validate that the MTU on the vSphere Distributed Switch (vDS) is set to a minimum of 1600.
In vSphere, validate that the MTU on the ESXi management interface (vmk0) is set to a minimum of 1600.
In vSphere, validate that the MTU on the vxlan interfaces on the hosts is set to a minimum of 1600.
Troubleshooting:
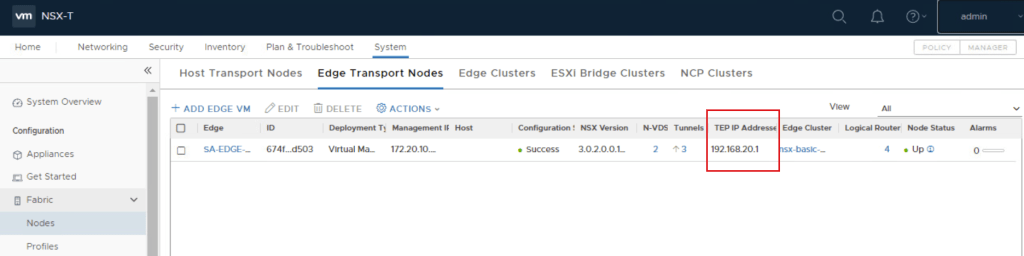
In the Tanzu enabled vSphere compute cluster, SSH into an ESXi host, and ping from the host’s vxlan interface to the edge TEP interface. This can be found in NSX-T via: System, Fabric and select Nodes, edge transport nodes, and find the edges for Tanzu. The TEP interface IPs will be to the right. In this lab, I only have the one edge. Production environments will have more.
In this example, vxlan was configured on vmk10 and vmk11 on the hosts. Your mileage may vary.
We are disabling fragmentation with (-d) so the packet will stay whole. We are using a packet size of 1600
If the ping is unsuccessful, we need to identify the size of the packet that can get through. Try a packet size of 1572. If unsuccessful try 1500. If unsuccessful try 1476. If unsuccessful try 1472, etc.
To test farther up the network stack, we can perform a ping something that has a different VLAN, subnet, and is on a routable network. In this example, the vMotion network is on a different network that is routable. It has a different VLAN, subnet, and gateway. We can use two ESXi hosts from the Tanzu enabled cluster.
Open SSH sessions to ESXi-01 and ESXi-02.
On ESXi-02, get the PortNum for the vMotion vmk. On the far left you will see the PortNum for the vMotion enabled vmk. Run the following command:
4. On the ESXi-01 session, use the vmkping command to ping the vMotion interface of ESXi-02. In this example we use a packet size of 1472 because that was the packet size the could get through, and option -d to prevent fragmentation.
# vmkping -I vmk0 -s 1472 -d <ESXi-02_vMotion_IP>
5. On the ESXi-02 session, we should now see six or more entries. Do a CTRL+C to cancel the packet capture.
6. Looking at the packet capture output on ESXi-02, We can see on the request line that ESXi-01 MAC address made a request to ESXi-02 MAC address.
On the next line for reply, we might see a new MAC address that is not ESXi-01 or ESXi-02. If that’s the case, then give this MAC address to the Network team to troubleshoot further.
Testing:
Using the ESXi hosts in the Tanzu enabled vSphere compute cluster, we can ping from the host’s vxlan interface to the edge TEP interface.
The edge TEP interface can be found in NSX-T via: System, Fabric and select Nodes, edge transport nodes, and find the edges for Tanzu. The TEP interface IPs will be to the far right.
You will need to know what host vmks the vxlan is enabled. In this example we are using vmk10 and vmk11 again.
In this example we are using vmk10 and vmk11 again. We are disabling fragmentation with (-d) so the packet will stay whole. We are using a packet size of 1600. These should now be successful.
On the ESXi-01 session, use the vmkping command to ping something on a different routable network, so that we can force traffic out of the vSphere environment and be routed. In this example just like before, we will be using the vMotion interface of ESXi-02. Packet size of 1600 should now work. We still use option -d to prevent fragmentation.
# vmkping -I vmk0 -s 1600 -d <ESXi-02_vMotion_IP>
On the developer VM, you should now be able to download the vsphere-plugin.zip from the vSphere with Tanzu landing page with the wget command.
Blog Date: June 17, 2021 Tested on vSphere 7.0.1 Build 17327586 vSphere with Tanzu Standard
The Issue:
On a recent customer engagement we ran into an issue when we applied the CA signed certificate to the vSphere with Tanzu enabled cluster. The customer could reach the Tanzu Landing Page (internal Kubernetes site address) with the assigned IP, and they received the secure lock on the site. However, they received an invalid certificate warning when trying to connect to the internal Kubernetes site with the FQDN. Upon closer inspection we realized that the FQDN is not apart of the certificate Subject Alternative Name (SAN). We had also found that this customer had MTU inconsistencies in their environment, and we ended up redeploying vSphere with Tanzu a couple of times. There will be another blog post for that, but in regards to this blog, on the last deployment we missed adding the FQDN during the setup.
The Cause:
When enabling vSphere with Tanzu on a compute cluster, during the deployment wizard, you are asked for the API Server endpoint FQDN (fully-qualified domain name). You will notice this says “Optional”.
However, because this value was not filled out during the deployment, it will not be in the SAN when you create a CSR to apply a certificate to the Tanzu supervisor cluster.
Resolution:
Currently the only “easy” fix for this would be to redeploy vSphere with Tanzu on the cluster assuming you are early on in the deployment.
However, if you have already deployed workloads this will be destructive. Your only other option is to open a ticket with VMware GSS, and they will need to add the missing entry to the database on the vCenter.
I wouldn’t expect there to be a public KB article on this as we do not want customers editing the vCenter database without GSS guidance. There is currently no way to add the missing API Server endpoint FQDN in the UI. As of 6/16/2021, I heard an unconfirmed rumor that a feature request has been added for this, and there will be an option to edit this in the UI. However, there’s currently no ETA on when it will be added.
A big shout-out to Nicholas M. in GSS for helping me to resolve. Even though I cannot share the full resolution here, I can at least help others troubleshoot.
Advanced Troubleshooting:
If you really need to confirm that this is your issue, we can open a putty session to the vCenter.
2. Next we can check the database to to find what MasterDNSName was entered during the time of deployment. In my test, I only have a single compute cluster that has vSphere with Tanzu enabled. Your mileage may vary if you have more than one cluster enabled. Enter the following command to view the table. We are not making changes here.
# PGPASSFILE=/etc/vmware/wcp/.pgpass psql -U wcpuser -d VCDB -h localhost -x -c "select desired_config from cluster_db_configs where cluster like 'domain-c%';" | less
3. Initially you will see a bunch of lines on your console. If you hit the “page down” key once or twice to get past these lines (if needed, lowercase g to go back to the top). Look for MasterDNSNames. This would be the API Server endpoint FQDN. If the value = null, the API Server endpoint FQDN was left blank during the setup.
You cannot edit this. This however will confirm that the api server endpoint FQDN was not entered during the initial deployment.
5. hit q to quit
As stated previously, if this is a fresh deployment, the easiest path forward would be to re-deploy vSphere with Tanzu on the compute cluster in vSphere.
If you already have running workloads, your only other option at this point would be to open a support request with VMware GSS.












You must be logged in to post a comment.