
Blog Date: 3/03/2021
Versions Tested:
vCSA: 7.0.1
ESXi: 7.0.1
Microsoft CA Server: 2016
Recently I had a customer that wanted to install their custom certificates on a new vCenter, and have it act as an Intermediate CA to install approved certificates on their hosts. This is common, but is something I have never done myself, so I ended up testing this out in my lab. In this long blog post, I will walk through:
- Generating a Certificate Signing Request (CSR) for the vCenter.
- Signing the request, creating the certificate using a standalone Microsoft CA.
- Creating a trusted root chain certificate.
- Installing the custom signed machine SSL certificate.
- Installing the custom signed VMCA root certificate.
- Renew host certificates and test.
Before we get started, it is worthwhile to note if you were unaware that there are different certificate modes in vSphere 7. Bob Plankers does a great job explaining these modes in the following VMware Blog: vSphere 7 – Certificate Management
I have done my best to focus the steps involved, and provided those below while testing this out in my home lab. Your mileage may vary.
_________________________________________________________________________________________________________
Snapshot the vCenter
We will be applying Custom Machine and Trusted Root certificates to the vCenter, and it is good practice to take a snapshot of the vCenter appliance beforehand.
_________________________________________________________________________________________________________
Testing vCenter Connection with WinSCP
We will be using WinSCP to transfer the files to and from the vCenter. You should validate that you can connect to yours first. If you are having problems connecting to the vCenter win WinSCP, follow this KB2107727.
_________________________________________________________________________________________________________
GENERATE CERTIFICATE SIGNING REQUEST (CSR)
Start an SSH session with the vCenter appliance, and enter “/usr/lib/vmware-vmca/bin/certificate-manager” to launch the utility. We want option #2

Enter “Y” at the prompt: Do you wish to generate all certificates using configuration file : Option[Y/N] ? :

Enter privileged vCenter credentials. The default administrator@vsphere.local will do the trick. Hit Enter key, then input the password and hit the enter key again.

If there is a valid certtool.cfg file that exists with your organizations information you can select N here.

Else if
IF there is no certool.cfg file or you would like to look at the file, use option “Y” here.
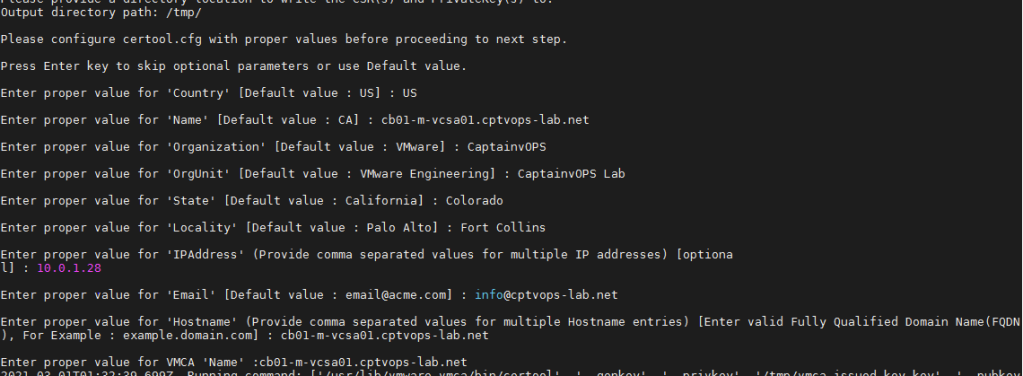
In the next series of prompts, you will be required to enter information specific to your environment. The inputs in purple below are examples I used for my lab, and yours will be different:
value for ‘Country’ [Default value : US] : US
value for ‘Name’ [Default value : CA]: cb01-m-vcsa01.cptvops-lab.net
value for ‘Organization’ [Default value : VMware]: CaptainvOPS
value for ‘OrgUnit’ [Default value : VMware Engineering]: CaptainvOPS Lab
value for ‘State’ [Default value : California]: Colorado
value for ‘Locality’ [Default value : Palo Alto] Fort Collins
value for ‘IPAddress’ (Provide comma separated values for multiple IP addresses) [optional]: 10.0.1.28
value for ‘Email’ [Default value : email@acme.com] : info@cptvops-lab.net
value for ‘Hostname’ (Provide comma separated values for multiple Hostname entries) [Enter valid Fully Qualified Domain Name(FQDN), For Example : example.domain.com] : cb01-m-vcsa01.cptvops-lab.net
Enter proper value for VMCA ‘Name’ : cb01-m-vcsa01.cptvops-lab.net
Enter option “1” to Generate Certificate signing requests
It will prompt for an export directory. In this example I used /tmp/

Now using WinSCP, copy the files off to the workstation you will be using to connect the the Microsoft CA.
_________________________________________________________________________________________________________
SIGNING THE REQUEST, CREATING THE CERTIFICATE USING STANDALONE MICROSOFT CA
I am using a standalone Microsoft CA I configured on my lab’s jump server, and don’t have the web portal. Launch the Certification Authority app.
Right-click the CA, select all tasks, and select Submit new request.

Once you browse to the directory where you stored the “vmca_issued_csr.csr” and “vmca_issued_key.key” files, you will need to change the view to “All Files (*.*)” in the lower right.
Now select the “vmca_issued_csr.csr”

Now go to “Pending Requests”. Right-click on pending cert request, go to “all tasks”, and select “Issue”.

Now go to “Issued Certificates”, double-click to open the certificate, go to the “details” tab and click the Copy to File… button.

When the wizard starts, click Next.
Select “Base-64-encoded X.509 (.CER), and Click Next

Click Browse

type in the file name and click save. In this example, I just use “vmca”.

Click Next, and then click Finish. Now click OK to close the wizard.
_________________________________________________________________________________________________________
CREATING A TRUSTED ROOT CHAIN CERTIFICATE
For this next part we will need the root certificate from the Microsoft CA. Right-click on the CA and select “Properties”

On the General tab, click the “View Certificate” button. Then on the new Certificate window that opens, click the details tab and then the “Copy to File…” button

When the wizard starts, click Next.
Select “Base-64-encoded X.509 (.CER), and Click Next
Just like before, browse to a locate to save the cert, and give it a meaningful name. In this example, I just use “root-ca”

Click Next and then click Finish. Close the windows.
In order to create a trusted root, we need to create a new file that has the root chain. This file will include the vmca.cer first, and then the root-ca.cer beneath it. I just open the vmca.cer file and root-ca.cer file with Notepad ++

Save it as a new file. In this example I use: vmca_rootchain.cer.

Using WinSCP, I create a new directory in the vCenter’s root directory called CertStore, and then copy the “vmca.cer”, “vmca_rootchain.cer”, and the “vmca_issued_key.key” there.
_________________________________________________________________________________________________________
INSTALLING THE CUSTOM MACHINE SSL CERTIFICATE
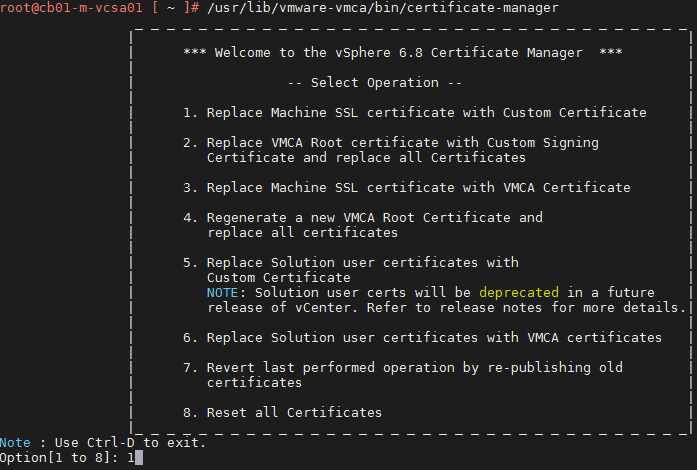
Open an SSH session to the vCenter, launch the certificate-manager: “/usr/lib/vmware-vmca/bin/certificate-manager”. First we will replace the Machine SSL certificate, so select option 1
Again we are prompted for vCenter authoritative credentials, and just like before we’ll use the administrator@vsphere.local account and password.
Now we reach the menu where we will use Option 2 to import custom certificates. Hit enter.

It will prompt for the directory containing the cert file for the Machine SSL. In this example I used: /CertStore/vmca.cer

Now it prompts for the custom key file. In this example I used: /CertStore/vmca_issued_key.key

Now it will ask for the signing certificate of the Machine SSL certificate. Here we will use the custom vmca_rootchain.cer file we created earlier: /CertStore/vmca_rootchain.cer

Respond with “Y” to the prompt: You are going to replace Machine SSL cert using custom cert
Continue operation : Option[Y/N] ? :

Assuming all of the information in the files was correct, the utility will begin replacing the machine SSL certificate. Watch the console for any errors and troupleshoot accordingly. 9 out of 10 times fat fingers are the cause for errors. Or dumb keyboards..
In my case it finished successfully.

_________________________________________________________________________________________________________
INSTALLING THE CUSTOM SIGNED VMCA ROOT CERTIFICATE
Relaunch the certificate-manager: “/usr/lib/vmware-vmca/bin/certificate-manager”. Use Option #2 now.

Enter Option: Y

Enter the authoritative vCenter account and password. Just like before I’m using the administrator@vsphere.local

We already have a known good certool.cfg file. We’ll skip ahead to the import, so use option: N

Use option #2 to import the custom certificates.

We are prompted for the custom certificate for root. Here we will use the custom vmca_rootchain.cer file we created earlier: /CertStore/vmca_rootchain.cer

Here we are prompted for the valid custom key for root. Just like last time we will use: /CertStore/vmca_issued_key.key

Use option “Y” to replace Root Certificates at the next prompt

Now the utility will replace the root certificate.

_________________________________________________________________________________________________________
TESTING THE VSPHERE CERTIFICATE
After clearing the browser cache, we can see the secure padlock on the login page for vSphere 7.

Now log into vSphere, go to Administration, and Certificate Management. Depending on how quickly you logged in after applying the certs, you may see an error on this page. Give it up to 5 minutes, and you’ll see a prompt at the top of the screen asking you to reload. Do it. Now you will see a clean Certificates Management screen. You should see a _MACHINE_CERT with your organization’s details. You will also see three Trusted Root Certificates. One of which will have your Organizations details.

_________________________________________________________________________________________________________
RENEW HOST CERTIFICATES AND TEST
If you have hosts already attached to the vCenter, and you would like to “Renew” the certificate, by default you will need to wait 24 hours before the certificate can be updated. Otherwise you will receive a similar error in vCenter:

If you need to update the certificate right away, follow KB2123386 to change the setting from 1440 to 10. This will allow for updating the ESXi certificate right away. I’d personally change it back after.
Either 24 hours has passed, or you followed the KB2123386 mentioned above. Now you can “Renew” the certificate on the ESXi host(s). You’ll see the Issuer of the certificate has changed, and should reflect your information. This operation doesn’t appear to work while the host is in maintenance mode.

If you browse to the ESXi host, it too will now have a padlock on its login page signifying a valid certificate.











You must be logged in to post a comment.