
Blog Date: January 16, 2024
One of my customers was interested in tracking datastore over-provisioning in Aria Operations, since they started deploying all of their virtual machines with thin-provisioned disks. After doing some digging, I found there is a Overcommit ratio metric for datastores, so in this blog I will review the creation of a custom view that we will then use in a report.
In Aria Operations under Visualize -> Views, create a new view. In this example, we’ll just call it Datastore Overcommit. Click NEXT
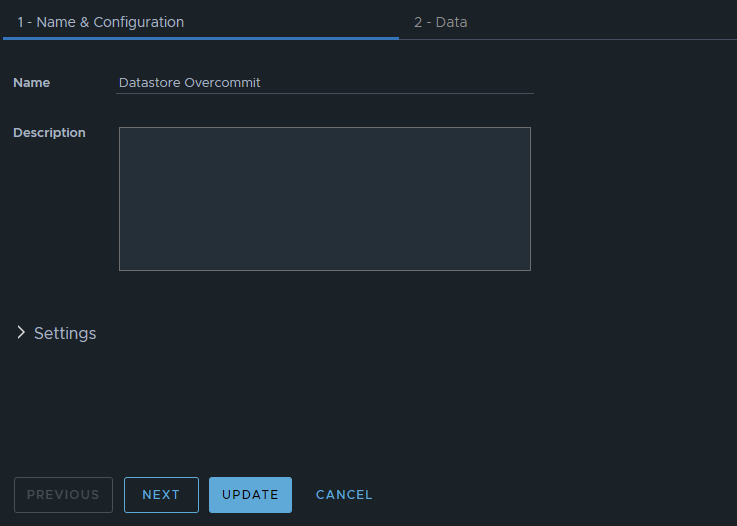
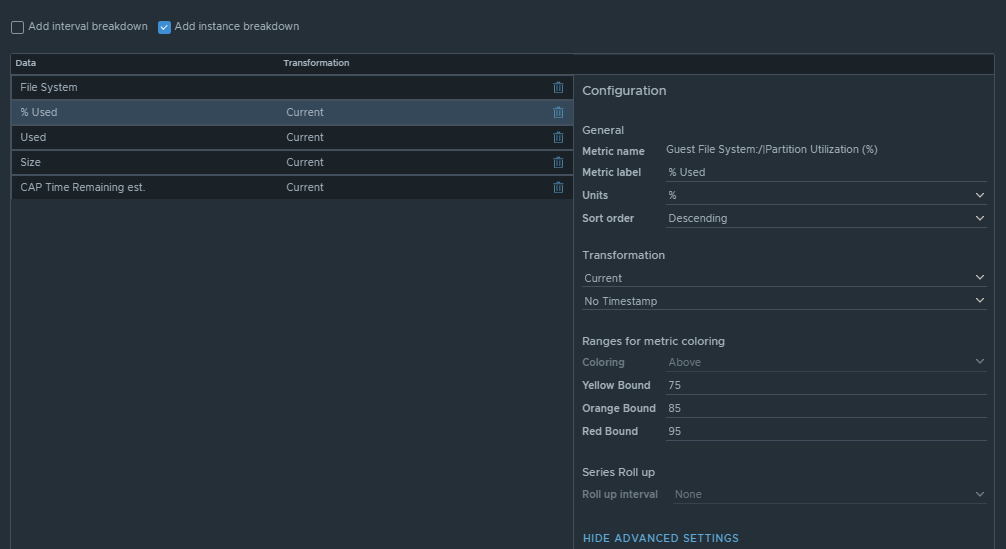
Now we can select the metrics desired. We will want to add the subject of “vCenter | datastore”, and then you could also group by “vCenter|Datastore Cluster” if you desire. For this example, I have selected the following datastore metrics:
Metric: “Summary|Parent vCenter”. Label: “vCenter”
Metric: “Disk Space|Total Capacity (GB)”. Label: “Total Capacity”. Unit: “GB”
Metric: “Disk Space|Total Provisioned Disk Space With Overhead (GB)”. Label: “Provisioned Space”. Unit: “GB”
Metric: “Disk Space|Virtual Machine used (GB)”. Label: “Used by VM”. Unit: “GB”
Metric: “Disk Space|Freespace (GB)”. Label: “Freespace”. Unit: “GB”
Metric: “Summary|Total Number of VMs”. Label: “VM Count”. Unit: “GB”
Metric: “Disk Space|Current Overcommit Ratio”. Label: “Overcommit Ratio”. Sort Order: “Descending” Coloring Above: Yellow Bound: “1”. Orange Bound: “1.3”. Red Bound: “1.5”
The end result should look something like this:
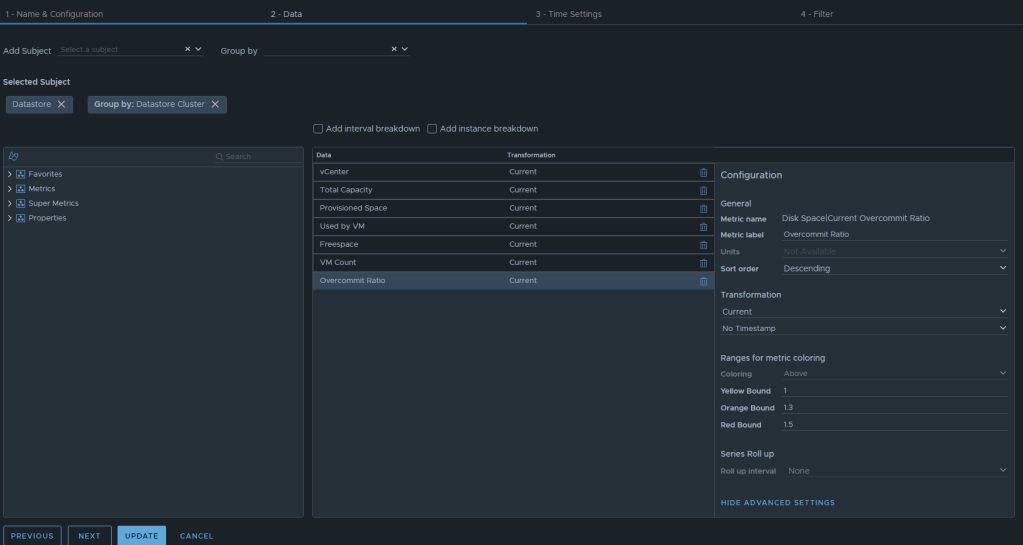
I typically will set the Preview Source as “vSphere World” to see the output data I am getting.
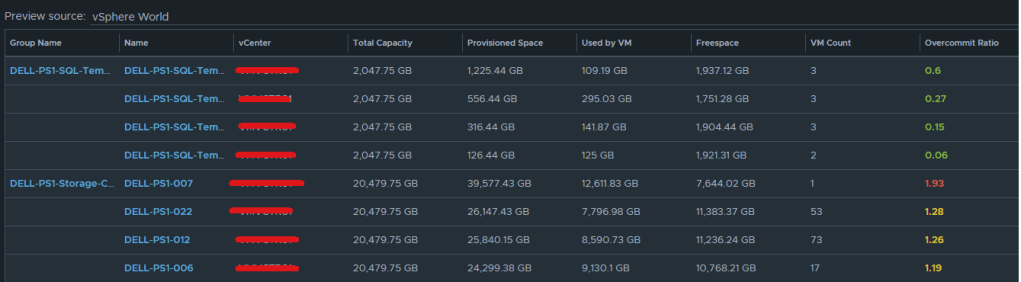
If you don’t like the datastores being grouped by the datastore cluster, then just undo the grouping option, and all of the datastores that are the worst overcommit offenders will rise to the top. The view can now be saved.
Creating an Aria Operations Report.
In Aria Operations, Under Visualize -> Reports, create a new report. In this example we call it Datastore Overcommitment.
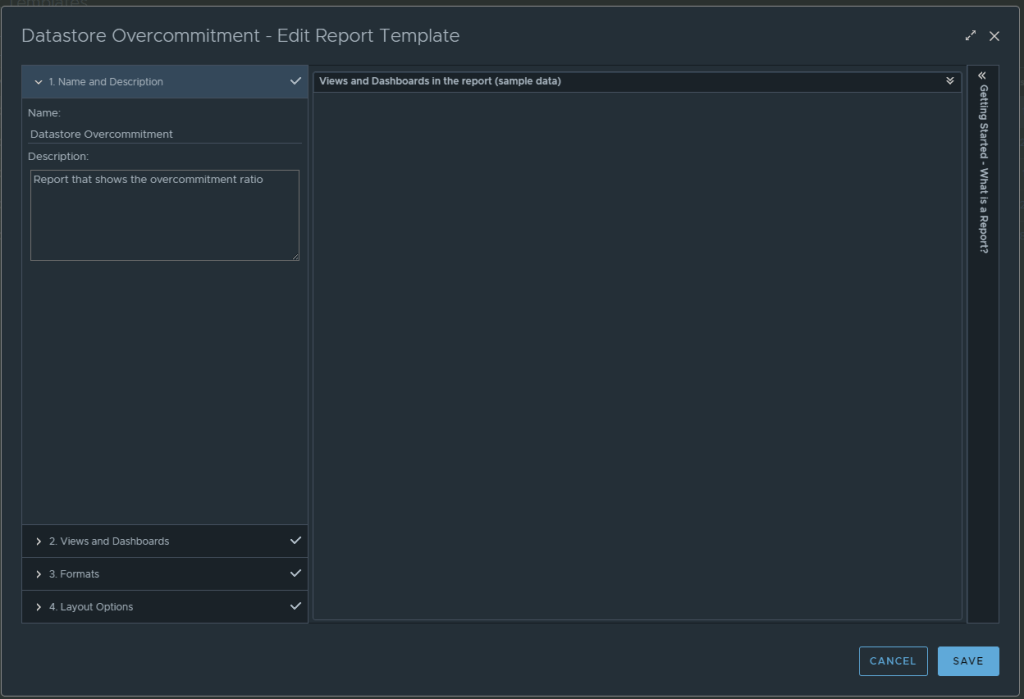
In section 2 for views and dashboards, I searched for datastore and found the newly created “Datastore Overcommit” view created earlier. I dragged it to the right. I changed the Orientation to landscape, and turned on Colorization.
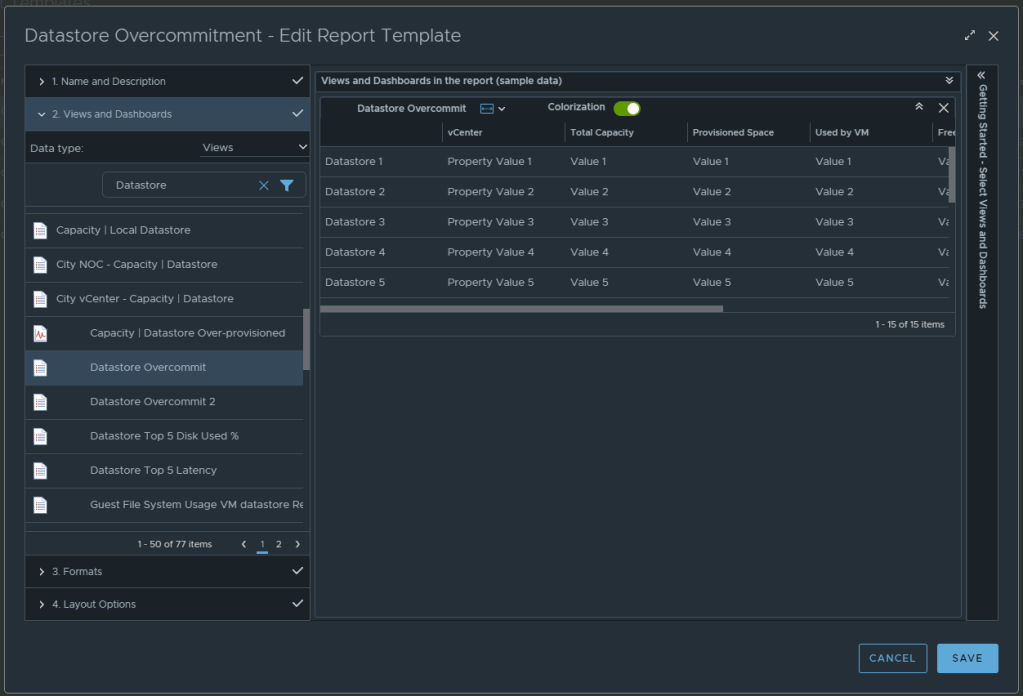
From here, under section 3 you can select the format of the report PDF and/or CSV, and then under section 4 you can elect to add a cover page and what not. I personally like getting a PDF and CSV. Now can click SAVE to save the report.
From here, you can run the report or schedule it. It’s that simple.










You must be logged in to post a comment.