vmware’s annual party was held at the T-Mobile arena in Las Vegas this year.

Great entertainment, however the convention ran out of food pretty quick at several kiosks. This year’s entertainment was a band from New Jersey called Bleachers who put on a decent show.

The main headliner for the night was Blink-182. Certainly not the band I remember growing up, but they hit a lot of the songs from my youth.

On Thursday, the last day of the conference, vmware invited several guests on stage to discuss the future of science and technology.

The first speaker discussed the advancement of facial recognition, and the desire to track human emotions. The ability to have artificial intelligence (A.i) understand empathy, and the ability to deliver digital content based on the emotional preferences of the viewer. Although this session was cool, I personally feel that this technology is dangerous to pursue.
- Delivering digital content to the viewer based on their viewing habits feels as if it would lead us to an era where people become emotionally numb. If people are not shown content that exposes them to the full spectrum of emotions, it feels as if society would become even more disconnected from the world around them.
- Giving A.I the ability to show empathy, and more huminized emotions may not be a bad thing if the proper requlations are in place. I think as we become more escustomed to having our robotic companions, this would certainly make thss frustrating to use.

The second speaker discussed the advancement in prosthetics. This was probably the most exciting keynote I’ve watched.
- The speaker discussed his double leg amputation in his early twenties due to frostbite while mountain climbing. He discussed his research at MIT where not only did he design his own prosthetics, but began a journey with colleagues that will ultimately change the future of prosthetics. They identified a problem with the current generation and the lack of true innovation.
- The speaker also discussed the crude method surgeons still currently use that prevents the rewiring of the human body, to feel the prosthetic, and to be able to flex and use it as if it were a real limb. He then went on to show a new surgical procedure that allows the human body to do just that, and it was truly inspiring.
The final speaker of the keynote was a pediatric surgeon discussing the advancement of surgical “batting practice” where the teams practicing surgical procedures on patients is now finally becoming a thing of the past, and instead surgeons have teamed up with Hollywood special affects organizations.
- This partnership has allowed the creation of life like surgical dummies that allows surgeons to practice in preparation for the real thing. This allows surgeons to tackle complex cases, theories procedures, and then order these surgical dummies to suit these theories, and the patients specific medical condition.
- They can then perform the multiple procedures, attend after action meetings to discuss, and ultimately find the best surgical solution for the patient. This ultimately allows the surgeon to discuss these findings with families before even asking them to come to the hospital for the procedure, giving them the confidence that the surgical teams have practiced of their child’s specific condition.



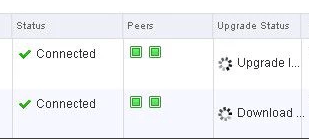
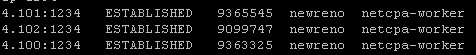
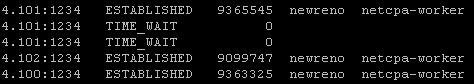



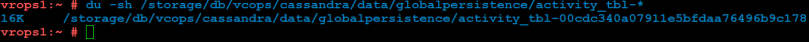





You must be logged in to post a comment.