
Blog Date: December 2025
One of the things that I had been waiting for were the VMware Cloud Foundation 9 subscription licenses for VMUG Advantage members and the vExpert community of bloggers and SMEs. VMUG Advantage Home Lab License Guide During the week of November 17th, it was announced that the download tokens are now available for the VMUG Advantage Members who passed their VCF 9 certifications.
This post assumes that you have already deployed the VCF Installer, and are ready to get those VCF 9 bits downloaded to your home lab like a typical production environment would.
- Your VMUG Advantage account email has to be the same as the one that you use with your VMware by Broadcom certifications.
- To access your VMUG Advantage VCF or VVF entitlements go here and log in: https://support.broadcom.com/group/ecx/alpine-certificate
- After you authenticate, there’s a good chance that your session has been redirected to the Broadcom Support Portal. Past the above URL back into your browser and hit enter…
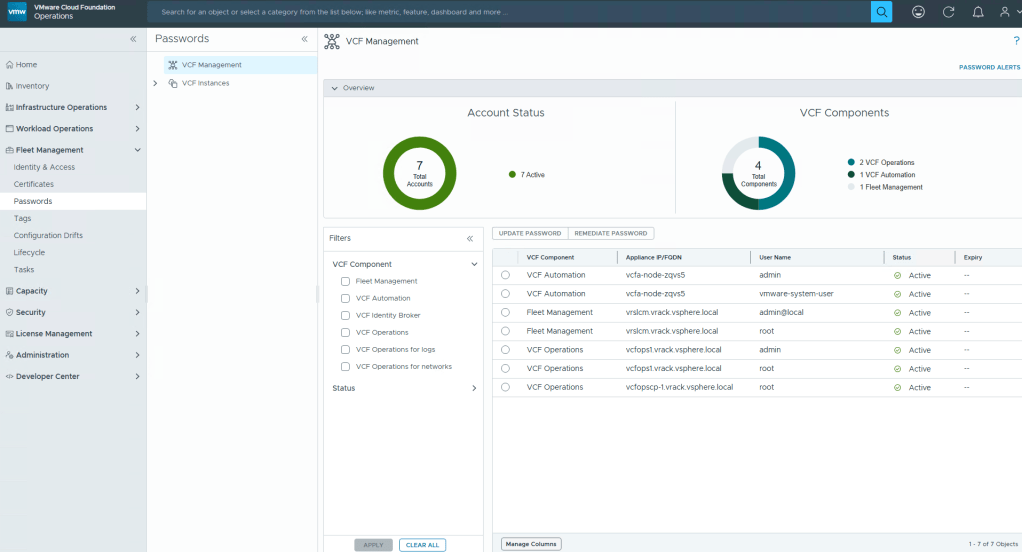
- You should have now arrived at the special VMUG Advantage portal and see the VCF Certification Production Licenses in the upper left of the screen like so:
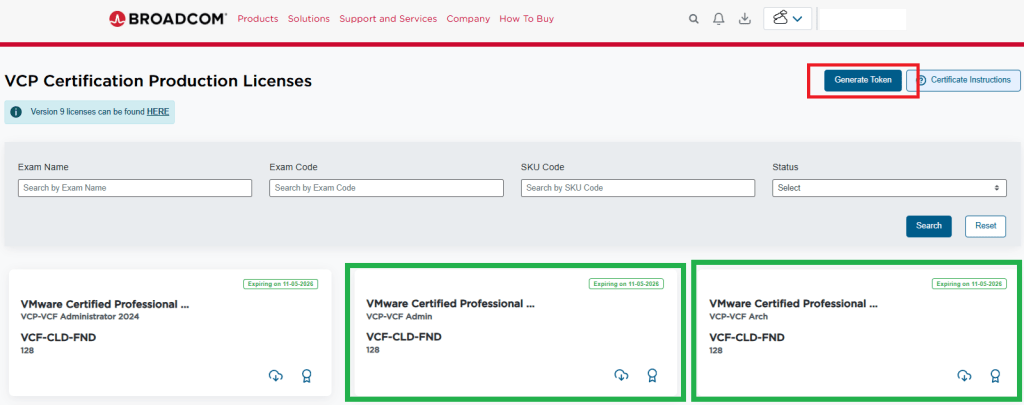
I have already requested my licences for VCF, and thus have a badge and a cloud download button on the green highlighted boxes. If you do not see those, then you would see a blue request license button. This post assumes you already have done this.
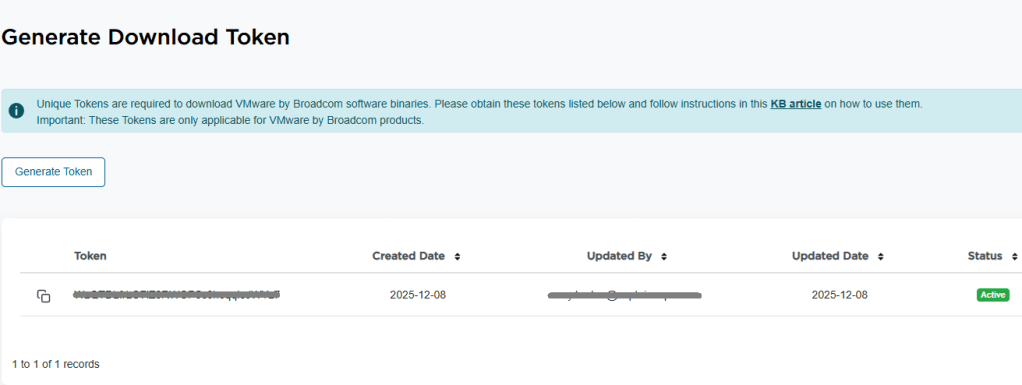
5. In the top right of the window, you see a blue “Generate Token” button. Click it.
6. On the next screen, you should see the download token needed for the VCF Installer. Copy it.
7. Log into the VCF installer appliance.
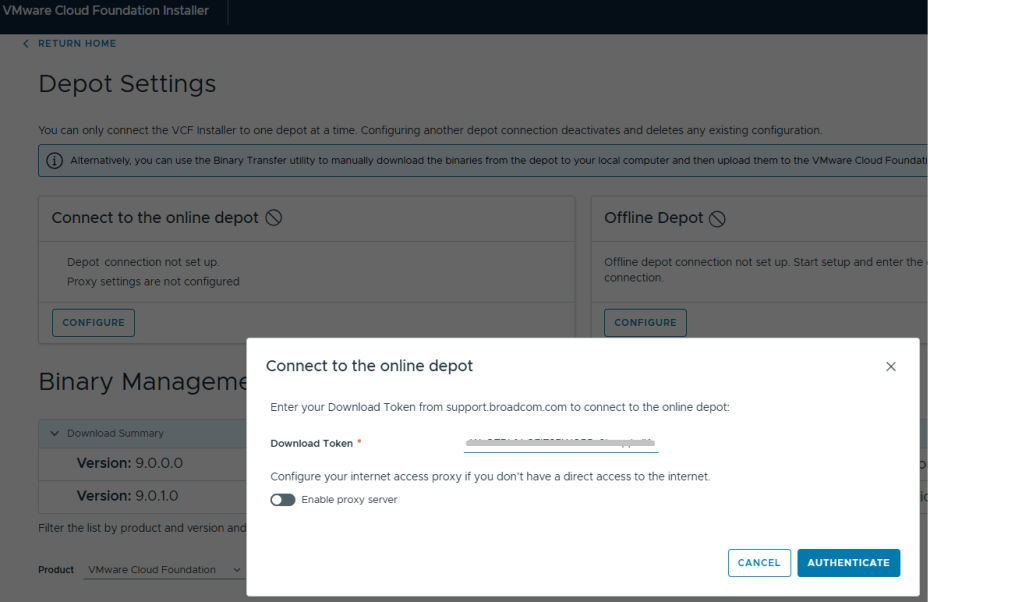
8. Go into Depot Settings, and click ‘Configure’ on the Connect to the online depot.
9. Paste the download token and click the blue ‘Authenticate’ button.
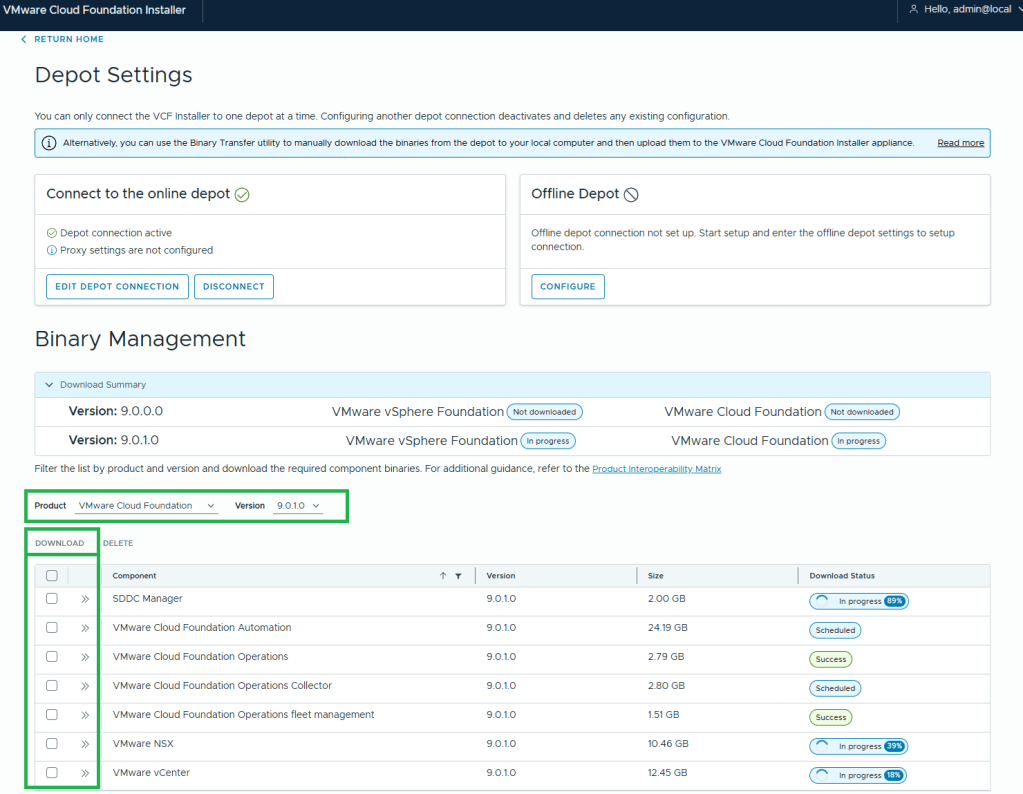
10. Assuming your VCF Installer can reach the internet and depot, a connection will be established.
11. In this example, I want to download the Product “VMware Cloud Foundation” and Version “9.0.1.0”.
12. Select all the bits desired for download, and then click the ‘DOWNLOAD’ link.
VMware by Broadcom has made this process more difficult. All of the required bits for installation used to be included with the Cloud Builder appliance that was available for VCF 5 and older versions. Now there’s an extra step to download the bits, but I’m sure that was a feature of the required download token. More complexity.










You must be logged in to post a comment.