
Blog Date: December 2025
In this post I’ll cover the basic ESX host prep needed for VMware Cloud Foundation. This post assumes that ESX 9 has already been installed. This post also assumes these are brand new hosts that have not been used for vsan before.
Configure the ESX Host basic network settings via the DCUI
- Open the DCUI of the ESX host.
- Open a console window to the host.
- Press F2 to enter the DCUI.
- Log in using the esx_root_user_password.
- Configure the network.
- Select Configure Management Network and press Enter.
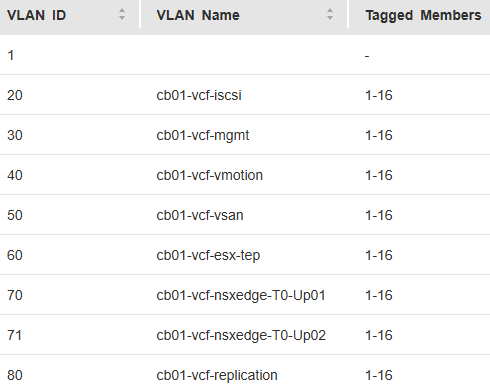
- Select VLAN (Optional) and press Enter.
- Enter the VLAN ID for the ESX Management Network and press Enter.
- Select IPv4 Configuration and press Enter.
- Select Set static IPv4 address and network configuration and press the Space bar.
- Enter the IPv4 Address, Subnet Mask and Default Gateway and press Enter.
- Here I would also disable IPv6 if not in use.
- Select DNS Configuration and press Enter.
- Select Use the following DNS Server address and hostname and press the Space bar.
- Enter the Primary DNS Server, Alternate DNS Server and Hostname (FQDN) and press Enter.
- Select Custom DNS Suffixes and press Enter.
- Ensure that there are no suffixes listed and press Enter.
- Press Escape to exit and press Y to confirm the changes.
- Reboot the host.
- Repeat this procedure for all remaining hosts.
Configure the Virtual Machine port group on the standard switch
- In a web browser, log in to the ESX host using the VMware Host Client.
- Click OK to join the Customer Experience Improvement Program.
- Configure a VLAN for the VM Network port group.
- In the navigation pane, click Networking.
- Click the Port groups tab, select the VM network port group, and click Edit Settings.
- On the Edit port group – VM network page, enter the VM Management Network VLAN ID, and click Save.
- Repeat this procedure for all remaining hosts.
Configure NTP on the Host(s)
- In a web browser, log in to the ESX host using the VMware Host Client.
- Configure and start the NTP service.
- In the navigation pane, click Manage, and click the System tab.
- Click Time & date and click Edit NTP Settings.
- On the Edit NTP Settings page, select the Use Network Time Protocol (enable NTP client) radio button, and change the NTP service startup policy to Start and stop with host.
- In the NTP servers text box, enter the NTP Server FQDN or IP Address, and click Save.
- Click the Services tab, select ntpd, and click Start.
- Repeat this procedure for all remaining hosts.
Regenerate Self-Signed Certificate on ESX Hosts.
- In a web browser, log in to the ESX host using the VMware Host Client.
- In the Actions menu, click ServicesEnable Secure Shell (SSH).
- Log in to the ESX host using an SSH client such as Putty.
- Regenerate the self-signed certificate by executing the following command:
#:/sbin/generate-certificates - Reboot the ESX host.
- Log back in to the VMware Host Client and click ServicesDisable Secure Shell (SSH) from the Actions menu.
- Repeat this procedure for all remaining hosts.
I don’t know why, but every customer engagement that I have been on, these steps get overlooked. This is probably the simplest part to preparing your data center for VCF. VMware by Broadcom also has documentation with these exact steps located here: Preparing ESX Hosts for VMware Cloud Foundation or vSphere Foundation










You must be logged in to post a comment.