It’s that time of year again, time for VMworld in Las Vegas. I will make every attempt at updating my blog throughout the week. See you there!

Upgrading NSX from 6.2.4 to 6.2.8 In a vCloud Director 8.10.1 Environment
We use NSX to serve up the edges in vCloud Director environment currently running on 8.10.1. One of the important caveats to note here, that when you do upgrade an NSX 6.2.4 appliance in this configuration, you will no longer be able to redeploy the edges in vCD until you upgrade and redeploy the edge first in NSX. Then and only then will the subsequent redeploys in vCD work. The cool thing about that though, is VMware finally has a decent error message that displays in vCD if you do try to redeploy an edge before upgrading it in NSX, you’d see an error message similar to:
—————————————————————————————————————–
“[ 5109dc83-4e64-4c1b-940b-35888affeb23] Cannot redeploy edge gateway (urn:uuid:abd0ae80) com.vmware.vcloud.fabric.nsm.error.VsmException: VSM response error (10220): Appliance has to be upgraded before performing any configuration change.”
—————————————————————————————————————–
Now we get to the fun part – The Upgrade…
A little prep work goes a long way:
- If you have a support contract with VMware, I HIGHLY RECOMMEND opening a support request with VMware, and detail with GSS your upgrade plans, along with the date of the upgrade. This allows VMware to have a resource available in case the upgrade goes sideways.
- Make a clone of the appliance in case you need to revert (keep powered off)
- Set host clusters DRS where vCloud Director environment/cloud VMs are to manual (keeps VMs/edges stationed in place during upgrade)
- Disable HA
- Do a manual backup of NSX manager in the appliance UI
Shutdown the vCloud Director Cell service
- It is highly advisable to stop the vcd service on each of the cells in order to prevent clients in vCloud Director from making changes during the scheduled outage/maintenance. SSH to each vcd cell and run the following in each console session:
# service vmware-vcd stop
- A good rule of thumb is to now check the status of each cell to make sure the service has been disabled. Run this command in each cell console session:
# service vmware-vcd status
- For more information on these commands, please visit the following VMware KB article: KB1026310
Upgrading the NSX appliance to 6.2.8
- Log into NSX manager and the vCenter client
- Navigate to Manage→ Upgrade
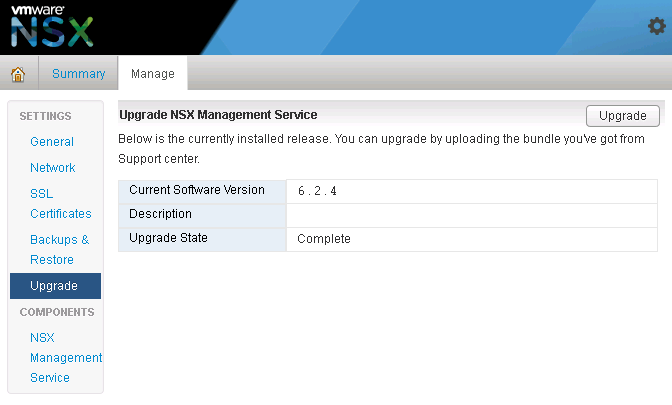
- Click ‘upgrade’ button
- Click the ‘Choose File’ button
- Browse to upgrade bundle and click open
- Click the ‘continue button’, the install bundle will be uploaded and installed.
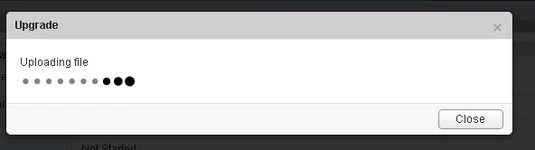

- You will be prompted if you would like to enable SSH and join the customer improvement program
- Verify the upgrade version, and click the upgrade button.
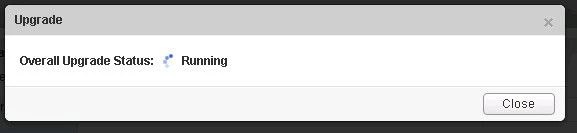
- The upgrade process will automatically reboot the NSX manager vm in the background. Having the console up will show this. Don’t trust the ‘uptime’ displayed in the vCenter for the VM.
- Once the reboot has completed the GUI will come up quick but it will take a while for the NSX management services to change to the running state. Give the appliance 10 minutes or so to come back up, and take the time now to verify the NSX version. If using guest introspection, you should wait until the red flags/alerts clear on the hosts before proceeding.
- In the vSphere web client, make sure you see ‘Networking & Security’ on the left side. If it does not show up, you may need to ssh into the vCenter appliance and restart the web service. Otherwise continue to step 12.
# service vsphere-client restart
12. In the vsphere web client, go to Networking and Security -> Installation and select the Management Tab. You have the option to select your controllers and download a controller snapshot. Otherwise click the “Upgrade Available” link.
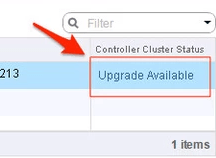
13. Click ‘Yes’ to upgrade the controllers. Sit back and relax. This part can take up to 30 minutes. You can click the page refresh in order to monitor progress of the upgrades on each controller.
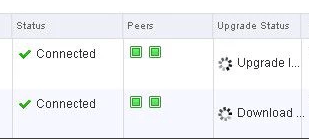
14. Once the upgrade of the controllers has completed, ssh into each controller and run the following in the console to verify it indeed has connection back to the appliance
# show control-cluster status
15. On the ESXi hosts/blades in each chassis, I would run this command just as a sanity check to spot any NSX controller connection issues.
esxcli network ip connection list | grep 1234
- If all controllers are connected you should see something similar in your output
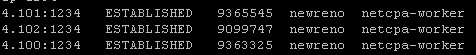
- If controllers are not in a healthy state, you may get something similar to this next image in your output. If this is the case, you can first try to reboot the controller. If that doesn’t work try a reboot. If that doesn’t work…..weep in silence. Then call VMware using the SR I strongly suggested creating before the upgrade, and GSS or your TAM can get you squared away.
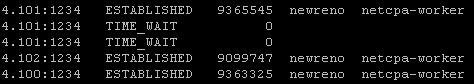
16. Now in the vSphere web client, if you go back to Network & Security -> Installation -> Host Preparation, you will see that there in an upgrade available for the clusters. Depending on the size of your environment, you may choose to do the upgrade now or at a later time outside of the planned outage. Either way you would click on the target cluster ‘Upgrade Available’ link and select yes. Reboot one host at a time that way the vibs are installed in a controlled fashion. If you simply click resolve, the host will attempt to go into maintenance mode and reboot.
17. After the new vibs have been installed on each host, run the following command to be sure they have the new vib version:
# esxcli software vib list | grep -E 'esx-dvfiler|vsip|vxlan'
Start the vCloud Director Cell service
- On each cell run the following commands
To start:
# service vmware-vcd start
Check the status after :
# service vmware-vcd status
- Log into VCD and by now the inventory service should be syncing with the underlining vCenter. I would advise waiting for it to complete, then run some sanity checks (provision orgs, edges, upgrade edges, etc)
VMware Fun Facts 2017
VMware Fun Facts 2017

VMware Fun Facts 2017
VMware started with 5 people in 1998 and now has over 20,000 people. Take a quick tour of VMware’s history with this fun facts animation. Learn more about life at VMware: https://careers.vmware.com/ http://facebook.com/vmwarecareers http://twitter.com/vmwarecareers http://instagram.com/vmwarecareers https://www.linkedin.com/company-beta/2988/life/
vSphere 6.5 Update 1 is out, here’s why you…
vSphere 6.5 Update 1 is out, here’s why you want to upgrade | Itzikr’s Blog on WordPress.com

vSphere 6.5 Update 1 is out, here’s why you…
Hi VMware have just released the first major update to vSphere 6.5, normally, I don’t blog on these but this update is so big and it fixes some really annoying bugs I saw using the GA version of vSphere 6.5..thankfully, we worked hard with their support to overcome some of the issues I highlighted in…
How To Get the Most Out of VMworld 2017 –…
How To Get the Most Out of VMworld 2017 — Virtualization Review

How To Get the Most Out of VMworld 2017 –…
There’s so much to do, see and learn at VMworld. Here’s your guide to navigating the show.
vExpert 2017 Second Half Announcement
vExpert 2017 Second Half Announcement

vExpert 2017 Second Half Announcement
Thank you to everyone who applied for vExpert. I’m pleased to announce the list of 2017 Second Half vExperts. Each of these vExperts have demonstrated significant contributions to the community and a willingness to share their expertise with others. Contributing is not always blogging or Twitter as there are many public speakers, book authors, script […] The post vExpert 2017 Second Half Announcement appeared first on VMTN Blog .
VMworld 2017 gatherings & parties!
VMworld 2017 gatherings & parties!

VMworld 2017 gatherings & parties!
VMworld is famous for its wide array of opportunities to connect with fellow attendees. From our VMworld Customer Appreciation Party — to Sponsor Events — to unofficial meet-ups and parties organized by the VMworld community, you’ll find plenty of options for spending time with friends or making new ones.
A First-Timer’s Guide to VMworld
A First-Timer’s Guide to VMworld

A First-Timer’s Guide to VMworld
Is this your first year attending VMworld? Have no fear! We’ve got everything you need to know. Apart from attending all the keynotes and all of your favorite sessions, we’re sharing some key tips for first-timers.
#VMTN TechTalks are filling up. Some are still…
#VMTN TechTalks are filling up. Some are still open though like @Gortees or @k00laidIT’s talks. Register here: https://t.co/zGoTFdUBVG

#VMTN TechTalks are filling up. Some are still…
#VMTN TechTalks are filling up. Some are still open though like @Gortees or @k00laidIT’s talks. Register here: https://t.co/zGoTFdUBVG

Performing A Database Health Check On vRealize Operation Manager (vROPS) 6.5
In a previous post I showed how you could perform a healthcheck, and possibly resolve database load issues in vROPs versions from 6.3 and older. When VMware released the vROPS 6.5, they changed the way you would access the nodetool utility that is available with cassandra database.
$VCOPS_BASE/cassandra/apache-cassandra-2.1.8/bin/nodetool --port 9008 status
For the 6.5 release and newer, they added the requirement of using a ‘maintenanceAdmin’ user along with a password file. The new command to check the load status of the activity tables in a vROPS 6.5+ is as follows:
$VCOPS_BASE/cassandra/apache-cassandra-2.1.8/bin/nodetool -p 9008 --ssl -u maintenanceAdmin --password-file /usr/lib/vmware-vcops/user/conf/jmxremote.password status
Example output would be something similar to this if your cluster is in a healthy state:

If any of the nodes have over 600 MB of load, you should consult with VMware GSS or a TAM on the next steps to take, and how to elevate the load issues.
Next we can check the syncing status of the cluster to determine overall health. The command is as follows:
$VMWARE_PYTHON_BIN/usr/lib/vmware-vcops/tools/vrops-platform-cli/vrops-platform-cli.py getShardStateMappingInfo
Example output:

The “vRealize Ops Shard” refers to the data nodes, and the Master and Master Replica nodes in the main cluster. The available status’ are RUNNING, SYNCING, BALANCING, OUT_OF_BALANCE, and OUT_OF_SYNC.
- Out of Balance and Out of Sync should be enough to open an SR and have VMware take a look.
Lastly, we can take a look at the size of the activity table. You can do this by running the following command:
du -sh /storage/db/vcops/cassandra/data/globalpersistence/activity_tbl-*
Example Output:
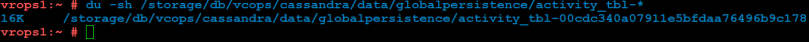
If there are two listed here, you should consult with VMware GSS as to which one can safely be removed, as one would be left over from a previous upgrade.

You must be logged in to post a comment.