Those of us who have taken the VMware Certified Professional Data Center Virtualization exams, can attest to those exams testing your knowledge and experience with vSphere, ESXi, and vSAN. We now have a new certification that tests our administration skills with VMware Cloud Foundation. Well, sort of…
What this exam got right: I do believe it was a good move to pull out questions regarding advanced deployment considerations around networking and VSAN stretch clusters, because those questions belong in a VCAP level exam that test our abilities around design and deployment. The exam also stayed away from questions that quiz us on deployment sizing, ports, and other factoids that in the real world, we would just consult the documentation for. I was also happy to see that there was significantly less “gotcha questions” than previous versions.
What I believe the exam got wrong: I do not believe this exam should have questions regarding the benefits and usage of add-ons like HCX, the Aria Suite, and Tanzu. To me, those questions should have been moved out to individual specialist exams that target those specific skillsets when used in conjunction with VCF. The exam did not go deep enough into the daily administration tasks like managing certificates and passwords, resolving trust issues between the SDDC manager and the VCF components like ESXi, vSAN, vCenter, and NSX. There should have been more questions on basic troubleshooting and questions regarding how to perform upgrades. These are basic administration skills that engineers should have, and are the area’s where I see engineers get themselves into trouble by coloring outside the VCF lines, especially coming from traditional vSphere environments with SAN storage.
Final thoughts: I do believe that this certification is a lot better than the VMware Cloud Foundation Specialist exams that have been retired, but this exam lacks focus on core skillsets necessary to administer VMware Cloud Foundation. This feels too much like an associate/specialist level exam. I would like to see a larger focus on testing an engineers skills administering VCF like what configurations should be done by the SDDC manager versus doing the configuration manually in the individual components. I would like to see questions that test an engineers basic VCF troubleshooting skills like what log files to look at for failed tasks and upgrades. The SOS command line tool in the SDDC manager is very powerful and VCF engineers should be aware of it’s basic functions. I would also like to see questions around the requirements and sequence of deploying hosts to a workload domain, decommissioning hosts, performing host maintenance, and some of the VSAN considerations engineers need to take into account for each. VMware Cloud Foundation is the modern private cloud, and although it is not feasible to have deep knowledge in each of the individual components that make up VCF like ESXi, vSAN, vCenter, vSphere, and NSX, I do believe we need to level-set on a basic set of skills to be successful.
I would highly recommend taking the VMware Cloud Foundation Administrator: Install, Configure, Manage 5.2 course. Many of the topics in the certification exam are covered in this training course. In its current form, you should also have a basic understanding HCX capabilities, and Aria Ops, Logs, and Automation. The exam also touches on the basic knowledge of the async patch tool and its function.
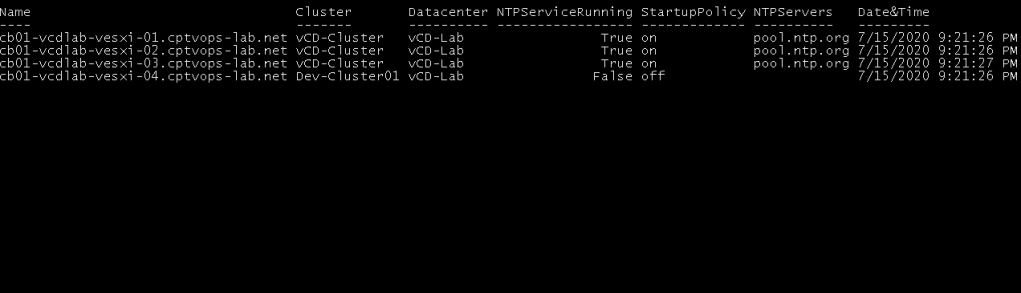
Quiet often when I connect to customer sites to conduct a health check, I sometimes find their hosts having different NTP settings, or not having NTP configured at all. Probably one of the easiest one-liners I keep in my virtual Rolodex of powerCLI one-liners, is the ability to check NTP settings of all hosts in the environment.
With this rather lengthy command, I can get everything that is important to me.
We can see from the output that I have a single host in my Dev-Cluster that does not have NTP configured. Quiet often I find customers that have mis-configured NTP settings, do not make use of host profiles that can catch and address issues like this.
If you also wanted to see the incoming, outgoing and protocols settings, you could use the following:
Most likely you would have multiple corporate NTP servers you’d need to point to, and that is easily done by separating them with a comma. An example of having two: Instead of having just ‘pool.ntp.org’ I’d have ‘ntp-server01,ntp-server02’.
The next thing needed is the startup policy. VMware has three different options to choose from. on = Start and stop with host, automatic = start and stop with port usage, and off = start and stop manually. In my lab I have the policy set to on.
With that in mind, the following command I can make the NTP settings of all hosts consistent. This command assumes that I only have one NTP server. I am also stopping and starting the NTP service. It is also worth mentioning that each host that already has the ntp server ‘pool.ntp.org’, will throw a red error that the NtpServer already exists.
Prior to this blog post, blogged and walked through the steps of creating a NFS linux server using CentOS 7. You can find the link to that blog post here.
The VMware Cloud Director (vCD) platform is primarily used by service providers, as a cloud offering for their customers. Back when I worked for a service provider, the bulk of my experience came from the version 8.x days, when vCD was a software package to be installed on a Linux VM. Fast forward a few years, and I’ve started deploying vCD 9.7 and vCD 10 appliances for VMware customers, part of Professional Services engagements for VMware that I’ve been working on. Interestingly enough, both customers were not cloud providers, but had specific use cases that vCD achieved.
The vCD appliance deployment certainly is not as clean as other appliances like vCSA and vROps, and I’ve found there to be a few gotchas that can lead to a failed appliance deployment.
Deploying the vCD appliance
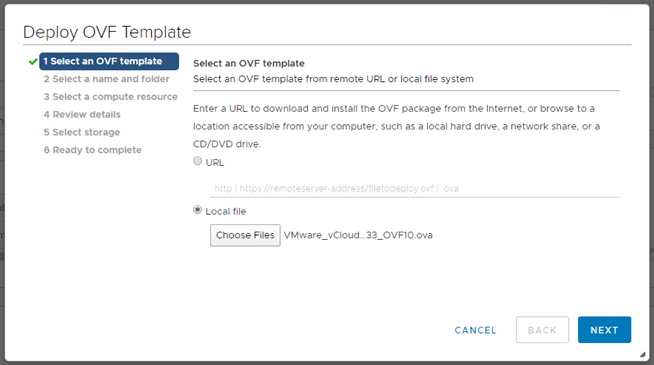
Like most appliance deployments, we’ll deploy an ovf template.
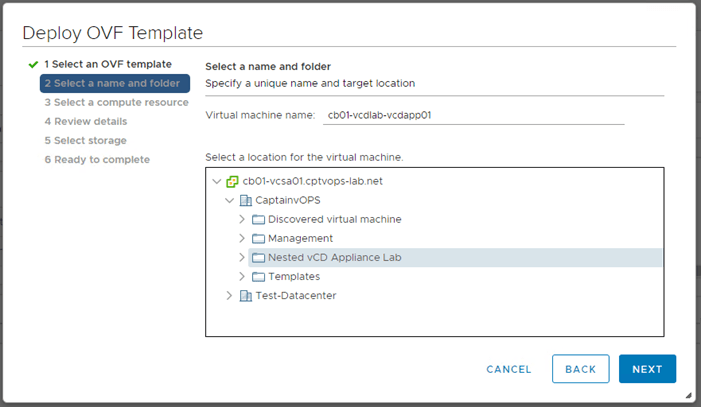
2. Name the virtual machine, and select desired deployment datacenter and VM folder location.
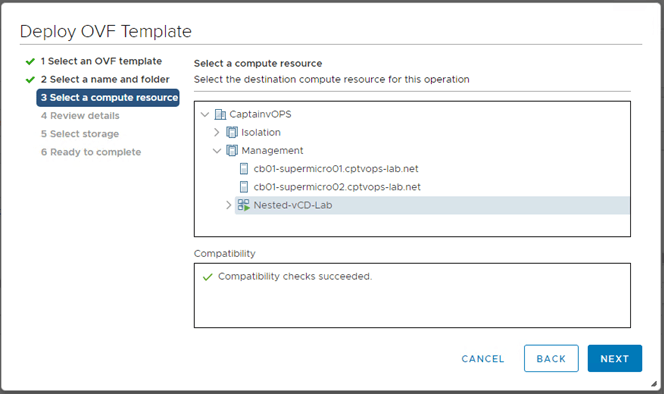
3. Select the desired compute location
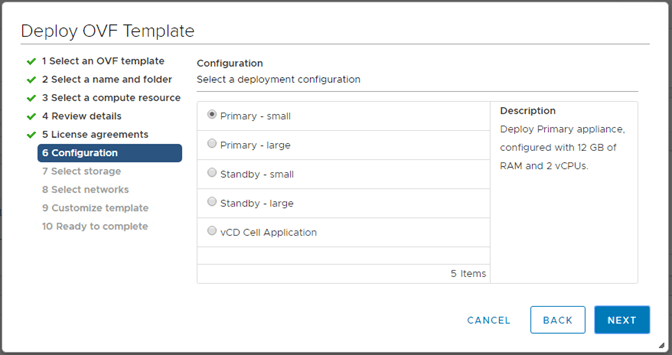
4. Select the size of the appliance. As this is the first primary cell, select an option that contains “primary”. If you are deploying appliance cells two and three, then you’d select “standby” here if you are creating a cluster. The “vCD Cell Application” would be used for the fourth appliance. – You’ll also notice two different sizes: Small and Large. These will depend on your environment needs. VMware’s official sizing documentation can be found here.
5. Select desired storage disk format and storage where the appliance will reside.
6. We’ve arrived at the first gotcha: Selecting the network. This is the only ovf deployment I’ve seen that lists the NICs in reverse order. VMware states in their official documentation that “the source network list might be in reverse order. Verify that you are selecting the correct destination network for each source network.” I have yet to see the networks display in the proper order. VMware also states that eth0 and eth1 must be on separate networks in their documentation here. I’ve asked GSS but wasn’t given an answer why. I haven’t found an issue with both connections being on the same network, but for demonstration purposes we’ll do as the official documentation says. Note: I have noticed at least in my lab that the appliance uses eth1 to connect to the NFS server.
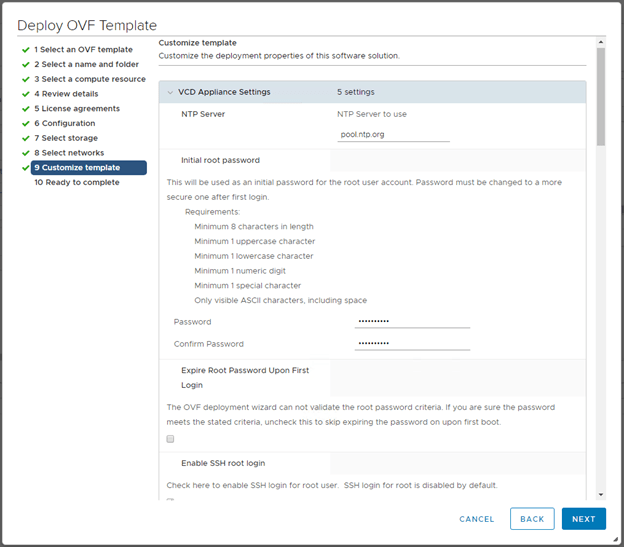
7. The second gotcha: Filling out the template customization page. It’s not indicated here that ALL fields are REQUIRED. Yes even the email address is a hard requirement, even though no other appliance deployment requires it.
8. On the summary page, verify the deployment and click finish.
9. Before starting the appliance, it may be a good idea to take a snapshot. Once the appliance has been started, and the configuration scripts attempt to run and fail, the appliance will need to be redeployed.
10. Once you have started the appliance, watch for the “Guest OS Initialization Script”. This should take a couple of minutes to run in order to be successful. If it runs for less than 10 seconds, then there was a problem and the appliance will need to be redeployed.
10a – If the appliance failed to deploy, log into the appliance as root, and look at the /opt/vmware/var/log/vcd/setupvcd.log for details.
10b – On a successful run, you’d see something similar to:
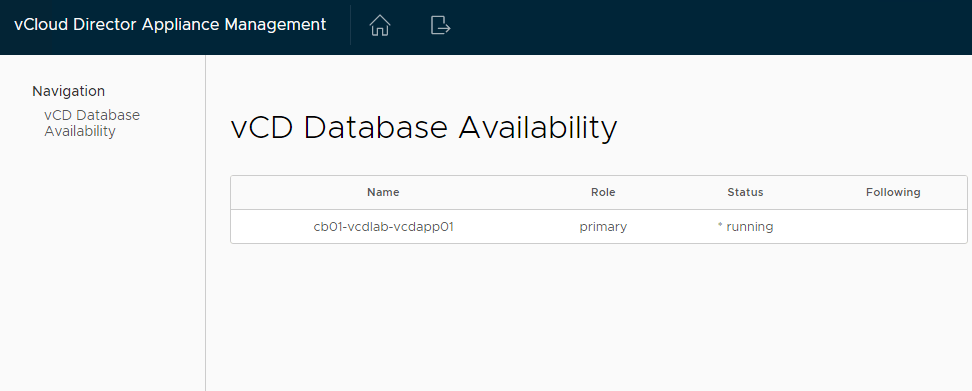
11 – On a successful deployment, log into the appliance 5480 page, and you should see something similar to:
12 – The primary appliance has successfully been deployed. If additional standby appliances are needed, now would be the best time to deploy them.
End – That’s it. In upcoming blog posts, I’ll walk through the process of deploying additional standby appliances, and the initial configuration of vCloud Director.
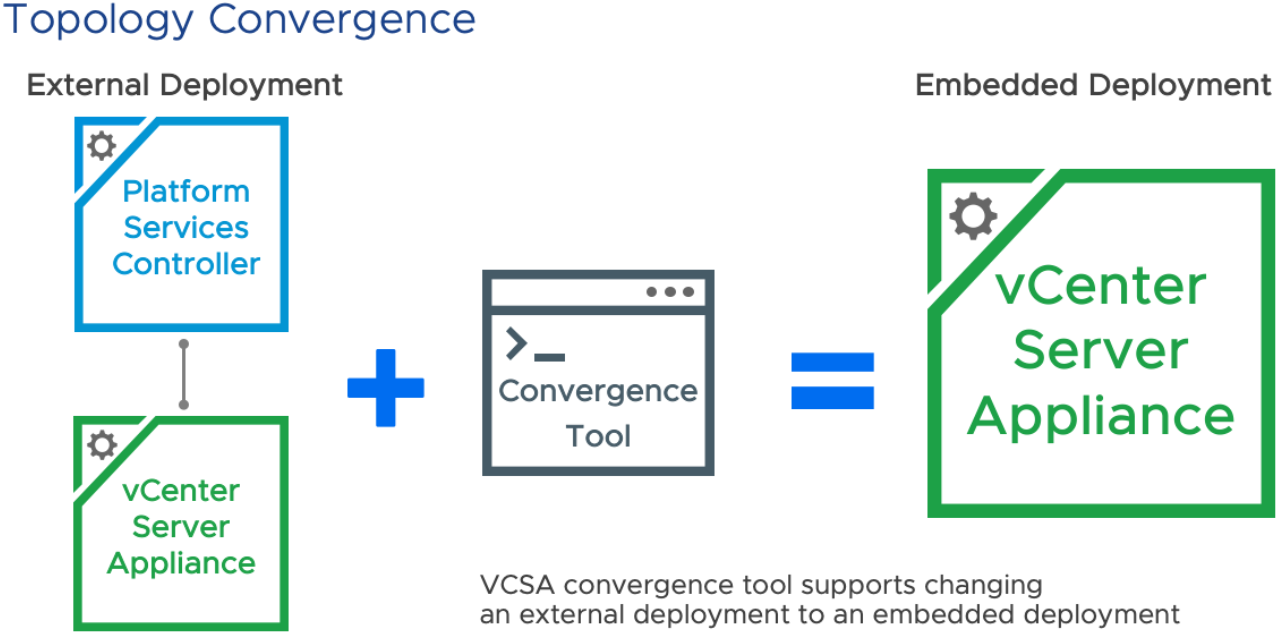
In this second part of the blog series “Upgrading to vSphere 6.7 Update 1, and Using the vCenter Converge Tool”, I will go over my experience using the Convergence tool. Lets get started.
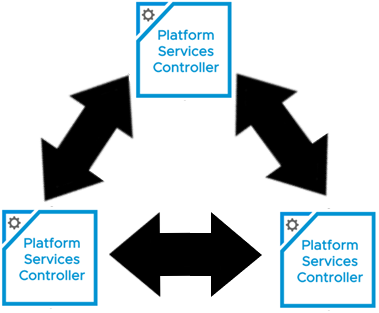
For this customer, I had three vCSA’s and three PSC’s that I needed to converge. Most of the blogs that I found didn’t cover PSC’s that were joined to a domain, environments with multiple vCenters, or with multiple PSC’s, so I thought I would write this up in a blog.
Planning the Convergence
The first thing I had to do was take note of any registered services with the SSO domain. I utilized VMware’s KB2043509 to identify these services, which I had none to worry about. VMware specifically calls out NSX and Site Recovery Manager (SRM), but since those were not in use at this customer, the only things I had to worry about were Horizon, vROps, vRLi and Zerto. Each of these services registered directly to the vCenters, so I had nothing to worry about there. If I had any services registered with the SSO domain, I’d simply need to re-register them once the convergence tool was ran. But since this didn’t apply, I can move forward with configuring the scripts for the convergence tool.
I also need to have an understanding of the replication typology of the existing SSO domain. VMware KB2127057 was an excellent resource I used to gather that information. Opening a putting session to a vCenter, and running the ‘vdcrepadmin’ command against each of the external PSCs, I was able to see the following:
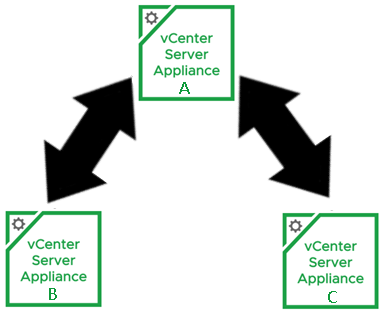
I can see they already have a ring topology, which is the desired architecture. If I were to draw the SSO typology out, it would look something like:
Setting Up the JSON Templates for the Convergence Tool
The converge.json template that the convergence tool uses, can be found in the VMware VCSA ISO, that was used for the 6.7 Update 1 upgrade, under the following path: DVD Drive (#):\VMware VCSA\vcsa-converge-cli\templates\
To make my life easier, I copied the contents of the entire ISO to a folder on the root of my C drive. I then made a seperate folder on the root of C called converge, and created a folder for each of the three vCenters I’d be working with: vCenter-A, vCenter-B, vCenter-C. I made a copy of the converge.json, and placed it into each folder.
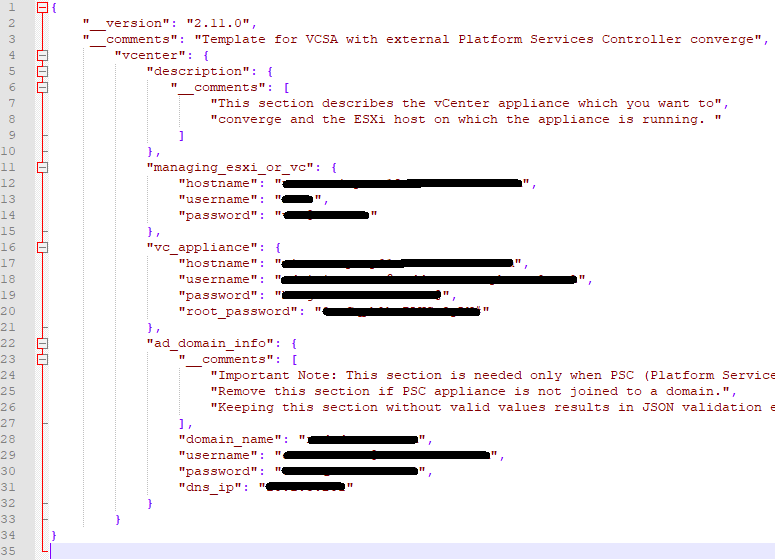
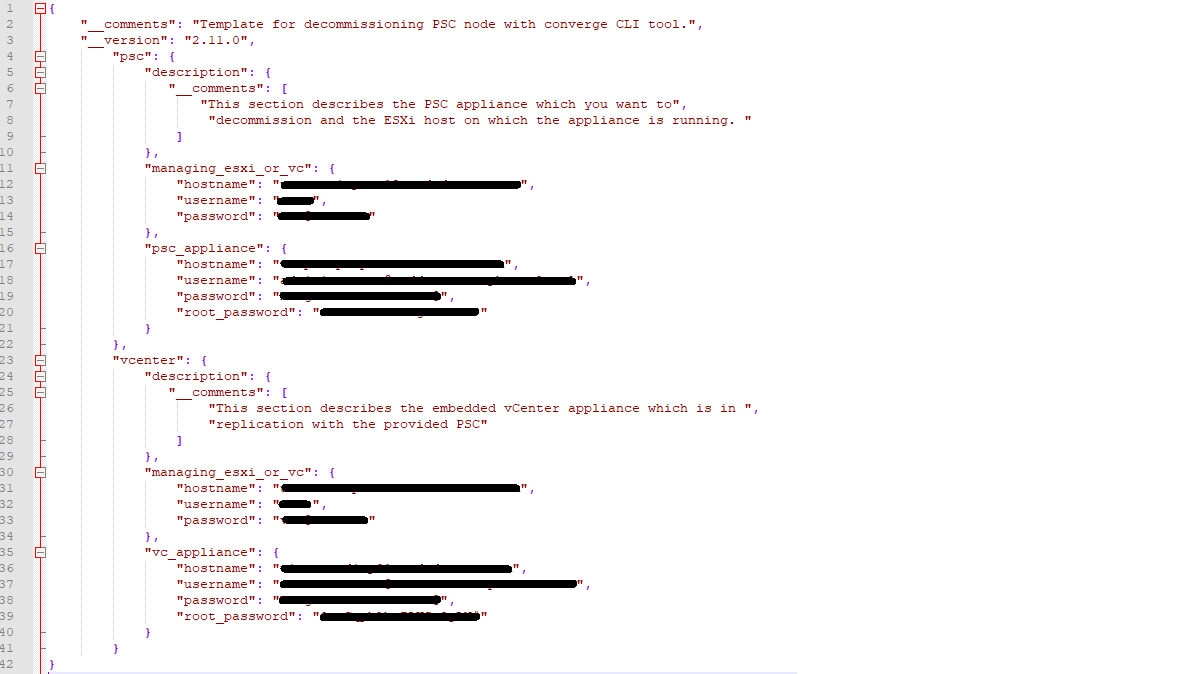
Taking a look at the converge.json for vCenter-A, the template tells you what data needs to be filled in, so pay close attention. Lines 10 – 15 needs entries for the ESXi host where the vCenter resides, or the managing vCenter appliance. Here I chose the option to used the Managing ESXi host. All I needed to do, was look in vSphere to see where the vCSA appliance VM resided on which host. While there, I also set the Cluster DRS settings to manual, to prevent the VMs from moving during the upgrade. Once I obtained the information needed, I completed that portion of the json. (I’ve redacted environment specific information).
Lines 16 – 21 need data entries for the first vCenter appliance (vCenter-A) to be converged. Here I need the FQDN for vCenter-A, for the Username, I need the administrator@vsphere.local account, its password, and the root password of the appliance.
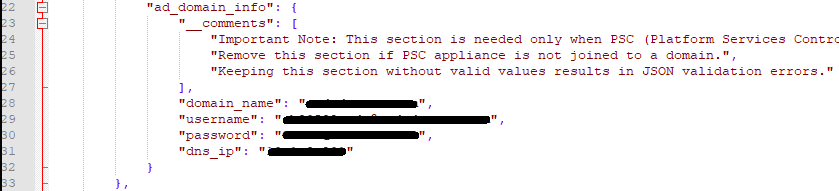
Lines 22 – 33 would be filled out IF the Platform Services Controller (PSC) appliance is joined to the domain. My customer was joined to the domain, so I needed to fill this section out. Otherwise you can remove this section from the JSON.
Now, because this is the first vCenter of three, in the same SSO domain, for the first convergence, I did not need this section, because the first vCenter does not have a partner yet. It will be needed however, on the second (vCenter-B) and third (vCenter-C) convergences.
Now I need to fill out a second and third converge.json file for the second and third convergence, saving each in its respective folder. For vCenter-B and vCenter-C, for the partner hostname on line 32, I used the FQDN of the first converged vCenter (vCenter-A), as that is the first partner of the SSO domain.
For vCenter-A, the first to be converged, the completed converge.json looks like this (take note of the commas, brackets and lines removed):
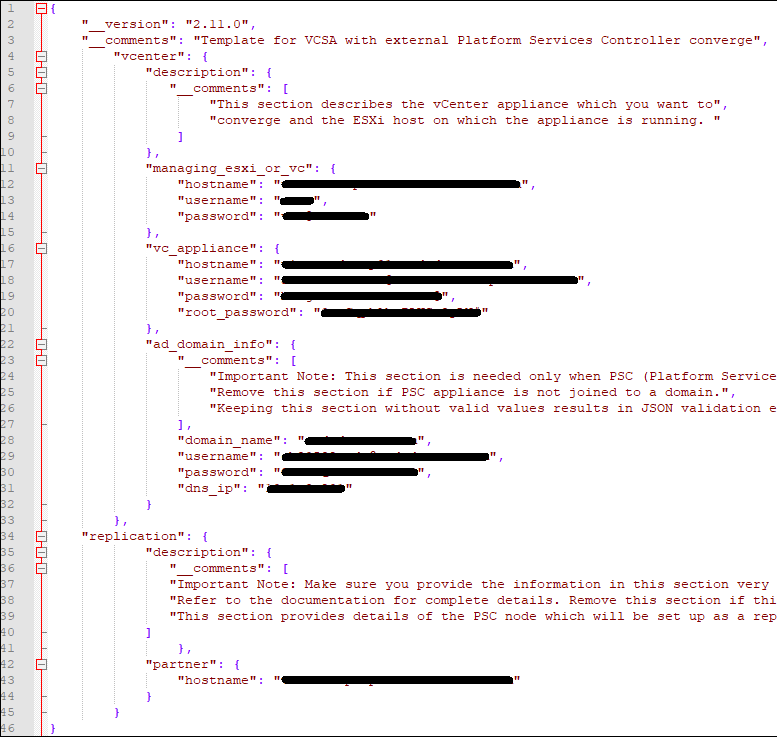
For the second convergence (vCenter-B), and third convergence (vCenter-C), the completed converge.json looks like this:
Now that we got the converge.json done for each of the vCenters, we can work on the decommission.json.
Here is the template VMware provides in the same directory:
Lines 11 – 15 require impute for the Managing vCenter or ESXi Host of the External PSC. Again, just like the vCenter, I used the ESXi host that the PSC is running on.
Lines 16 – 21 needs data for the Platform Services Controller that will be Decommissioned.
Lines 30 – 34 requires information for the vCenter the PSC was paired with. Again here I just used the ESXi host that the vCenter is currently running on
Lines 35 – 39 require the information for the vCenter, the PSC is paired with.
Now that we have the decommission.json filled out for the first vCenter (vCenter-A), I have to repeat the process for the second and third vCenters (vCenter-B, vCenter-C). The full decommission.json should look like
Now that both the converge.json and decommission.json have been filled out for each of my environments (3), and stored in the same directory on the root of C, I can move forward with the Convergence process.
Prerequisites and Considerations Before Starting the Convergence Process
The converge tool only supports the VCSA and PSC 6.7 Update 1. All nodes must be on 6.7 Update 1 before converting.
If you are currently running a Windows vCenter Server or PSC, you must migrate to the appliance first.
Before converting, take a backups of your VCSA(s) and PSCs in the vSphere SSO domain(VM snapshots, and DB backups).
Know all other solutions using the PSC for authentication in the environment. They will need to be re-registered after the convergence completes and before decommissioning.
A machine on a routable network which can communicate with the VCSA and PSC will be used to run the convergence and decommission process.
Set the DRS Automation Level to manual, and the Migration Threshold to conservative. There will be be issues if the VCSA being converged is moved during the process.
If VCHA is enabled, it must be disabled prior to running the convergence process.
The converge process will handle PSC HA load balancers. Make sure you point to the VIP in the JSON template if you have them.
All vSphere SSO data is migrated with the exception of local OS users.
Best to take snapshots of the vCSA and external PSC VMs before continuing. We’ve already backed up the database, but it doesn’t hurt to have snapshots as well.
Executing the Converge Tool
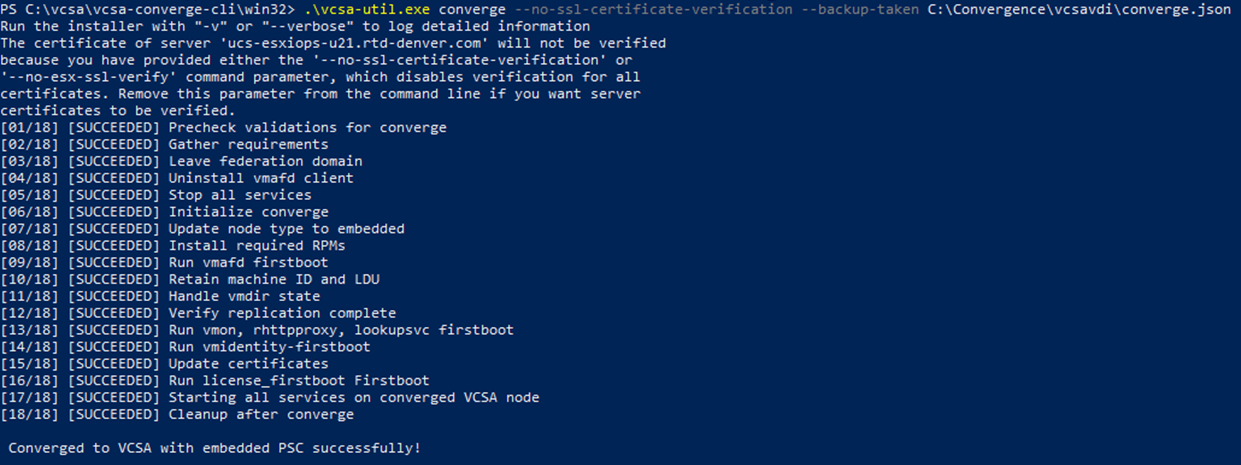
Now that converge.json template for each vCenter (vCenter-A, vCenter-B, vCenter-C) is filled out properly, we can now execute. We will run the convergence tool against the first vCenter (vCenter-A). Note: We can only run the converge tool against one vCSA at a time.
In powershell, we can first run the following command before proceeding with the upgrade to see what options/parameters are available with the converge tool.
The output in powershell should look something like:
It will then ask you to reboot the first vCenter before continuing.
Once the first vCenter (vCenter-A) came up, I executed the convergence tool for the second vCenter (vCenter-B). Once completed I restarted the appliance.
Finally, the last vCenter (vCenter-C) is on deck. I executed the converge.json against that vCenter, and once completed, I restarted it.
Here is where you would need to re-point those systems using the old SSO domain, but since I didn’t have any, I can move forward with the decommissioning steps.
Decommissioning the Old external Platform Services Controllers (PSC)
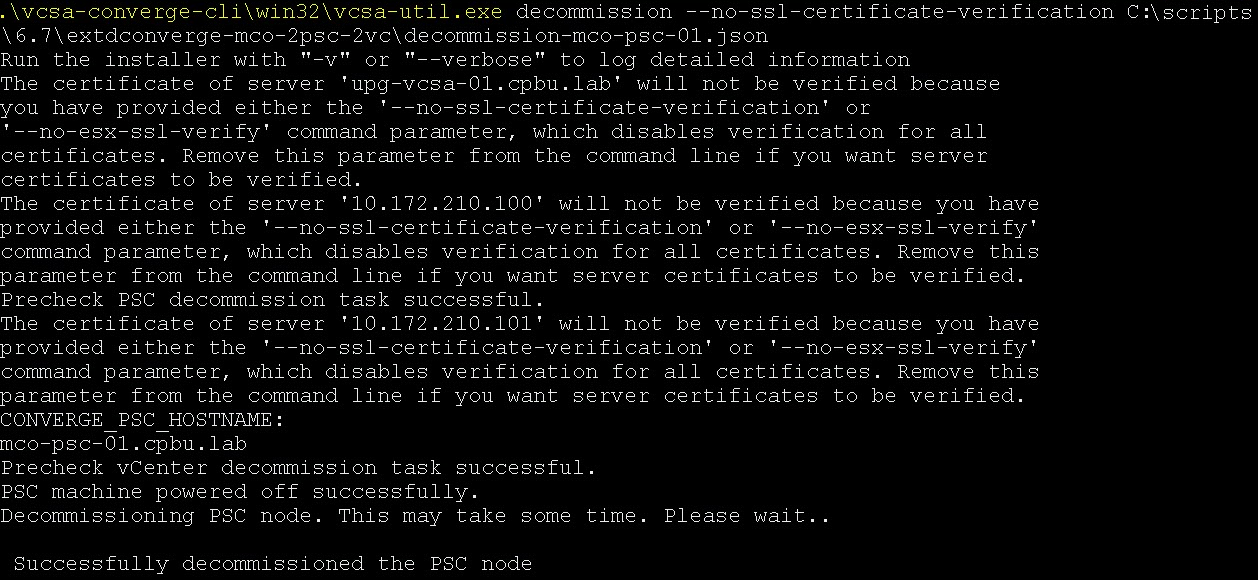
Using the Converge Tool with the decommission option to remove the external PSC’s. Just like before, we need to do this one PSC at a time. The command looks something like this:
Once the process successfully completes, move onto the next PSC. Repeat the process until all PSC’s have been decommissioned.
Validate the SSO Replication Topology After the Converge Process
If you’ll remember, when I setup the converge.json, I had the second vCenter (vCenter-B) and third vCenter (vCenter-C) replication partner set to the first converged vCenter (vCenter-A). My Replication topology currently looks like this:
I needed to close the loop between vCenter-B and vCenter-C. Using VMware’s KB2127057 , I used the ‘createagreement’ parameter. I opened a putty session to vCenter-B and ran the following command:
Now that the SSO replication agreement has been made between vCenter-B and vCenter-C, my replication topology looks like this:
I’m not going to lie, the hardest part of using the convergence tool, was just getting started. I’ve been through enough fires in my day to know how bad of a time I would have had if something went wrong, and I lost either the vCenter, or external PSC before the convergence successfully completed. Once I got myself beyond that mental hurdle, the process was actually quite easy and smooth.
I know I’ve left this customer’s environment in a lot better shape than I found it, and having embedded PSCs will make future vCenter upgrades a breeze. For a VMware PSO consultant, this was a huge value add for the customer.
I recently wrapped up a vSphere 6.7 U1 upgrade project, while on a VMware Professional Services (PSO) engagement, with a customer in Denver Colorado. On this project, I had to upgrade their three VMware environments from 6.5, to 6.7 Update 1. This customer also had three external Platform Services Controllers (PSC), a configuration that is now depreciated in VMware architecture.
Check the VMware Interoperability, and Compatibility Matrices
The first thing I needed to do, was to take inventory of the customer’s environment. I needed to know how many vCenters, if they had external Platform Services Controllers, how many hosts, vSphere Distributed Switch (VDS), and what the versions were.
From my investigation, this customer had three vCenters, and three external platform services controllers (PSC), all apart of the same SSO domain.
I also made note of which vCenter was paired with what external PSO. This information is critical not only for the vSphere 6.7 U1 upgrade, but also the convergence process that I will be doing in part two of this blog series.
Looking at the customer’s ESXi hosts, the majority were running the same ESXi 6.5 build, but I did find a few Nutanix clusters, and six ESXi hosts still on version 5.5.
The customer had multiple vSphere Distributed Switch (VDS) that needed to be upgraded to 6.5 before the 6.7 upgrade.
The second thing that I needed to do was to look at the model of each ESXi host and determine if it is supported for the vSphere 6.7 U1 upgrade. I also need to validate the firmware and BIOS each host is using, to see if I need to have the customer upgrade the firmware and BIOS of the hosts. We’ll plug this information into the VMware Compatibility Guide .
From my investigation, the three ESXi hosts running ESXi 5.5 were not compatible with 6.7U1, however they were compatible with the current build of ESXi 6.5 the customer was running on their other hosts. I would need to upgrade these hosts to ESXi 6.5 before starting the vSphere 6.7 U1 upgrade.
This customer had a mix of Dell and Cisco UCS hosts, and almost all needed to have their firmware and BIOS upgraded to be compatible with ESXi 6.7 U1.
The third thing I needed to check was to see what other platforms, owned by VMware, and/or bolt on third parties, that I needed to worry about for this upgrade.
The customer is using a later version of VMware’s Horizon solution, and luckily for me, it is compatible with vSphere 6.7 U1, so no worries there.
The customer has Zerto 6.0 deployed, and unfortunately it needed to be upgraded to a compatible version.
The customer has Actifio backup solution, but that is also running a compatible version, so again no need to update it.
Lets Get those ESXi 5.5 hosts Upgraded to 6.5
I needed to schedule an outage with the customer, as they had three offsite locations, with two ESXi 5.5 hosts each. These hosts were using local storage to house and run the VMs, so even though they were in a host cluster, HA was not an option, and the VMs would need to be powered off.
Once I had the outage secured, I was able to move forward with upgrading these six hosts to ESXi 6.5.
Time to Upgrade the vSphere Distributed Switch (VDS)
For this portion of the upgrade, I only needed to upgrade the customers VDS’s to 6.5. This portion of the upgrade was fast, and I was able to do it mid day without the customer experiencing an outage. We did submit a formal maintenance request for visibility, and CYA. Total upgrade time to do all of their VDS’s was less than 15 minutes. Each switch took roughly a minute.
Upgrade the External Platform Services Controllers Before the vCenter Appliances
Now that I had all hosts to a compatible ESXi 6.5 version, I can move forward with the upgrade. I was able to do this upgrade during the day, as the customer would only lose the ability to manage their VMs using the vCenters. I made backups of the PSC and vCSA databases, and created snapshots of the VMs just in case.
I first needed to upgrade the external PSCs (3) to 6.7 U1, so I simply attached the vCSA.iso to my jump VM, and launched the .exe. I did this process one PSC at a time until they were all upgraded to 6.7 U1.
Upgrade the vCenter Appliances to 6.7 Update 1
Now that the external platform services controllers are on 6.7 U1, it is time to upgrade the vCenters. The process is the same with the exe, so I just did one vCenter at a time. Both the external PSC’s and the vCSA’s upgraded without issue, and within a couple of hours both the external PSC’s and vCSA’s had finished the vSphere 6.7 Update 1.
Upgrade Compatible ESXi Hosts to 6.7 Update 1
I really wanted to use the now embedded VMware Update Manager (VUM), but I either faced users who re-attached ISO’s to their Horizon VMs, or had administrators who were upgrading/installing VMware Tools. In one cluster I even happened to find a host that had improper networking configured compared to its peers in the cluster. Once I got all of that out of the way, I was able to schedule VUM to work its way down through each cluster, and upgrade the ESXi hosts to 6.7 Update 1. There were still some fringe cases where VUM wouldn’t work as intended, and I needed to do one host at a time.
Conclusion for the Upgrade
In the end, upgrading the customer’s three environments, vCSA, PSC and ESXi to 6.7 Update 1 took me about a couple of weeks to do alone. Not too shabby considering I finished ahead of schedule, even with all of the issues I faced. After the upgrade, the customer started having their Cisco UCS blades purple screen at random. After opening a case with GSS, that week Cisco came out with an emergency patch for the fnic driver, on the customer’s UCS blades, for the very issue they were facing. The customer was able to quickly patch the blades. Talk about good timing.
Part 2 Incoming
Part 2 of this series will focus on using the vCenter Converge Tool. Stay tuned.
The very long over due followup post to my The Home Lab entry made earlier this year. I did recently purchase another 64GB (2x 32GB) Diamond Black DDR4 memory to bring my server up to 128GB. I had some old 1TB spinning disks I installed in the box for some extra storage as well, although I will phase them out with more SSDs in the future. So as a recap, this is my setup now:
Motherboard
SUPERMICRO MBD-X10SDV-TLN4F-O Mini ITX Server Motherboard Xeon processor D-1541 FCBGA 1667
Initially when I built the lab, I decided to use VMware workstation, but I recently just rebuilt it, installing ESXi 6.7 as the base. Largely for better performance and reliability. For the time being this will be a single host environment, but keeping with the versioning, vCSA and vROps are 6.7 as well. Can an HTML 5 interface be sexy? This has come a long way from the flash client days.
I decided against fully configuring this host as a single vSAN node, just so that I can have the extra disk. However, when I do decide to purchase more hardware and build a second or third box, this setup will allow me to grow my environment, and reconfigure it for vSAN use. Although I am tempted to ingest the SSDs into my NAS, carve out datastores from it and not use vSAN, at least for the base storage.
Networking is flat for now, so there’s nothing really to show here. As I expand and add a second host, I will be looking at some networking hardware, and have my lab in it’s own isolated space.
Now that I am in the professional services space, working with VMware customers, I needed a lab that was more production. I’m still building out the lab so I’ll have more content to come.
FYI – VMware is making some major changes to their certification naming conventions. Changes take affect August 2018 for newly released certifications listed below, and are not retroactive. This will not affect the naming of existing certifications however.
VMware Certified Professional – Desktop and Mobility 2018 (VCP-DTM 2018)
VMware Certified Advanced Professional – Data Center Virtualization Deployment (VCAP-DCV 2018 Deployment)
VMware Certified Advanced Professional – Cloud Management and Automation Deployment (VCAP-CMA 2018 Deployment)
I decided to go with a Supermicro build as I wanted something power efficient, yet expandable, and this motherboard supports up to 128GB of ECC RDIMM DDR4 2133MHz server grade memory. Now with this setup, when I feel the need to expand out my lab, I can build two more nodes, and I’ll have a rather nice VSAN cluster. However I’m hoping the cost of DDR4 memory will have come down by then…
I did look at the Supermicro SYS-E300-8D and SYS-E200-8D style micro servers, but like most, I was concerned about the fan noise, and thus decided to go with a slightly larger chassis to get the larger fan. Honestly the fan in the unit I bought makes no more noise then a regular desktop computer.
Here’s my hardware:
Motherboard
SUPERMICRO MBD-X10SDV-TLN4F-O Mini ITX Server Motherboard Xeon processor D-1541 FCBGA 1667
First of all, I would like to say that I am honored to be among some of the brightest VMware community technologists for a second year. Secondly I would like to personally welcome the new additions to the vExpert family.
I’ve honestly debated using this platform to blog about things currently underway in my personal life, but the first step in solving any problem, is recognizing that there is one. If I am being completely honest, 2018 started pretty rough for me. Shortly after returning to work after being out for surgery, I was informed that the company that I had been working for, for the past three plus years was shifting its priorities, and downsizing due to our parent company’s merger. Unfortunately my position with the company was affected. The past three years, and eight months had been some of the most exciting in my career, both from a technology standpoint, and a people standpoint as well. In those three plus years, I quickly had to ramp up on VMware technologies and concepts that I had never used before in a large cloud service provider environment.
My time spent with this company has afforded me with hands on expertise in managing multiple virtual environments that exceeded 500 ESXi hypervisors, several vCenter server appliances, NSX appliances, vROPS clusters, and several vCloud Director environments, in data centers all over the world. I battled the on-call boogeyman in intense hand-to-hand combat, restored three production data centers affecting over a thousand vCloud Director and Zerto tenants, and got to work on several fun POCs including working with VMware engineering on deploying VMware’s vCloud Availability. It was an amazing ride, with some of the best teammates I ever had the pleasure to work with. In those three plus years, I found time to obtain my VCP6-DCV certification, start my own tech blog, and become an active member in the VMware community sharing my experiences, and learning from others. But when one door closes, another will eventually open to greater opportunities.
Recently I have been thinking a great deal about moving west for my next adventure in cloud computing, and I would be lying if I said Colorado wasn’t on my mind. My goal now is to continue contributing my passion for VMware technologies to the VMware community, to help others, and learn from others, while I search for my next career to elevate my skills even higher, and to help business adopt virtualization and cloud technologies.
As such, I am making plans to attend the Denver VMUG usercon in April. Hope to see you there.
If network scanners are deployed in your production environments, it may be necessary to white-list the vROps nodes, as the network scanners can bring the tomcat service to its’ knees, especially on active vROps clusters. In my case the network scanner was causing tomcat to crash, so when users would attempt to access the main vROps , they’d get the following error:
“Unable to connect to platform services”
While troubleshooting this issue, I went through the sizing of the cluster, performance, verifying there’s nothing backing up the vROps VMs, even made sure the datastores and specific hosts were health. Even tried replacing the “/usr/lib/vmware-vcops/user/plugins/inbound” directory and files on all nodes from the master copy in hopes that it would make the cluster healthy again and stop tomcat from panicking.
The following was discovered after reviewing the /var/log/apache2/access_log on the master:
Tomcat service is being pushed to the limits and using many more resources than planned. There is upwards of 10,000 requests in bursts from a single IP address. From the logs it certainly looks like an attack, but that’s coming from an internal IP address.
My advice – get your security team to white-list your vROps appliances.
To restart the web service on all vROps nodes either by issuing this command to each node: ‘service vmware-vcops-web restart’ , or log into the admin page, take the cluster offline and then back online.



































You must be logged in to post a comment.